
What are the components of AI?
Disclaimer: The thoughts and ideas presented in this course are not to be substituted for legal or ethical advice and are only meant to give you a starting point for gathering information about AI policy and regulations to consider.
Learning objectives:
- Understand what makes a good AI model
- Describe what makes a model accurate
- Understand fundamentals about what makes AI models computationally efficient
- Describe components of LLMs and other AI models and how training data is critical to their accuracy
Intro
What makes the AI chatbots’ performance today so vastly improved from previous chatbots? Like those that resembled office supplies and helped us write documents? In this chapter we’ll discuss some generalities of how AI works and what makes an AI tool good.

A good AI model is accurate – you need it to give answers that are correct or at least useful. They are also computationally efficient because we need them to give the answer back in a reasonable amount of time. We also don’t want to spend tons of money on the computation it takes for the chatbot to work.

What makes an AI model accurate?
Let’s talk about the basics of what makes an AI model accurate. In order to understand this, we need to discuss some principles behind Machine learning.

Picture you were teaching someone (like an AI model) to identify apples from bananas. The training data you might give them would be a series of apples and bananas and you would label which were bananas versus apples.

You could then test the model’s abilities ability to identify apples and bananas based on this training by giving them a fruit to identity. Assuming the fruit you gave them is reasonably identifiable from their training, they should accurately identify an apple.

However, if the test you give the model is outside the kind of data they were trained on, they might not do well with it. For example if you didn’t provide any green apples and then you test the model with a green apple. It may or may not succeed.

To address this gap in the model’s knowledge, you might add supplementary training data and retrain it so that it understands that apples could also be green.


However, this added training data may help for the identification of green apples, but if given something similar to an apple but not – say a pear. It may incorrectly identify a pear as an apple if it hasn’t ALSO been trained on pears.

This may feel silly to you – why couldn’t it identify a pear – but this is because you are a really well trained AI. (Actually just the I, you presumably aren’t artificial). You’ve seen lots of fruit in your life – you’ve collected a lot of training data on this task and have no problem identifying a pear from an apple.

But we could throw you off too.

When you look at this image of a hybrid apple-banana, if AI models could feel, this is how they would feel.
What makes an AI model efficient?
Let’s talk about the basics of what makes an AI model accurate. In order to understand this, we need to discuss some principles behind Machine learning.
Let’s return to apples.

With the above image, you don’t need much time to look at that picture and know that that is an apple. You don’t have to think about this for very long.

With the above image, you don’t need much time to look at that picture and know that that is an apple. You don’t have to think about this for very long. You didn’t take in one piece of information at a time.
This type of information processing is what neural networks are based on. Neural networks are when computers mimic how brains work to process information.

Think about how you’d read the following paragraph:


Did you read each word, in order from start to end?
OR
Did you pick out keywords by skimming and getting the gist? Maybe later going back to pick up context you missed?
The old way AI models worked is that they would read sequentially – from start to finish. And as you may sense, that is a slower way to read.
Alternatively, the new algorithms often use Attention mechanisms. These algorithms work analogous to skimming the input text.

However, you could also probably sense that just because the new way of attention mechanisms are faster doesn’t mean that for all uses they are more accurate – by skimming you sometimes can miss important information.
Regardless of that, let’s walk through more about this analogy to get a sense of how attention mechanisms can work.

First we might highlight keywords in this paragraph. And meanwhile the words and phrases that are processed would be chunked into units called “tokens” the most important tokens we would focus on first with those attention mechanisms we referred to.

When we connect these relationship between these words we might already start pulling out some of the meaning of this paragraph. Grabbing these relational words will help us piece together more meaning.
Lastly we might pull out some contextual information from the other words we left behind.

Let’s here it straight from an AI model. We asked bard to tell us what phrases it would pull out as keywords with attention mechanisms if we gave it this paragraph.

Without these recent advancements in attention mechanism algorithms, the large language models that we see today would not be possible. Its these computationally efficient mechanisms that have allowed large language models to be possible in addition to the physical hardware improvements in computing.
Putting it together
In summary, a good AI model is accurate – this is largely determine by its training data being high quality, relevant and properly processed.
A good AI tool is also computationally efficient. We need to use algorithms that can efficiently and properly process data.

Let’s talk about the process of an AI query in a general sense. If we give input like an image of an apple, the AI tool will observe that input. It will use its prior experience of training data to digest that input.
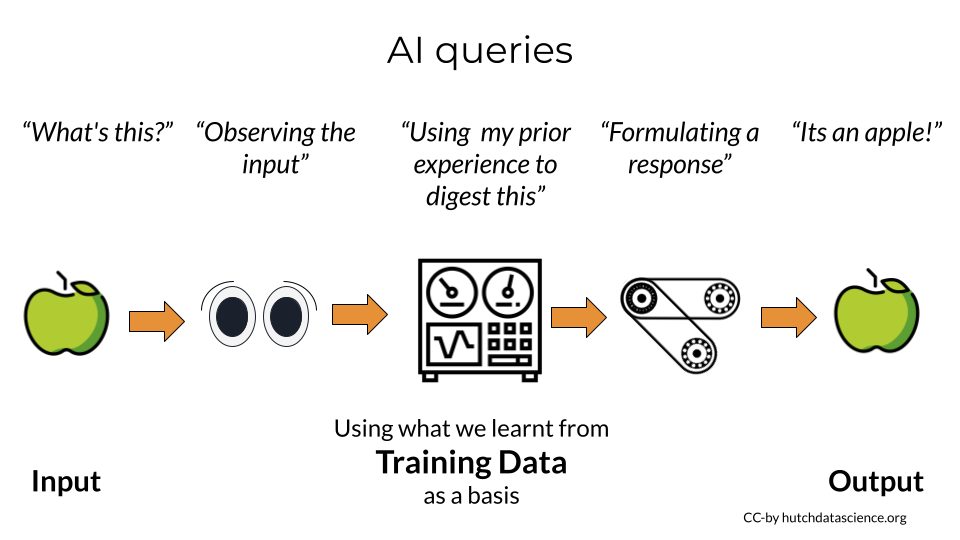
It will then formulate a response to return to us to tell us it’s conclusion. If it was trained properly, its returned response to us will be that it is indeed an apple.
We can then visualized a “machine learning machine” to describe AI. AI models can take a lot of different forms and functions and this visual is merely a tool to understand generalities about components of AI. It is not meant to be a detailed representation of any given AI model.
But we can discuss AI tools in terms of their:
- input what is the user of the tool providing?
- processing (including algorithms) – what are we going to do with that input?
- training data - how was the mode trained? what information was it trained on?
- output - what are we returning to the user of this AI tool?

Each of these components can get very complicated very quickly. Although we won’t go through the details of these in this course, we will discuss practical aspects of these in terms of customization for AI needs.
Large language models are one popular type of AI tool. So we can talk about the components of these models in the context of this visual.
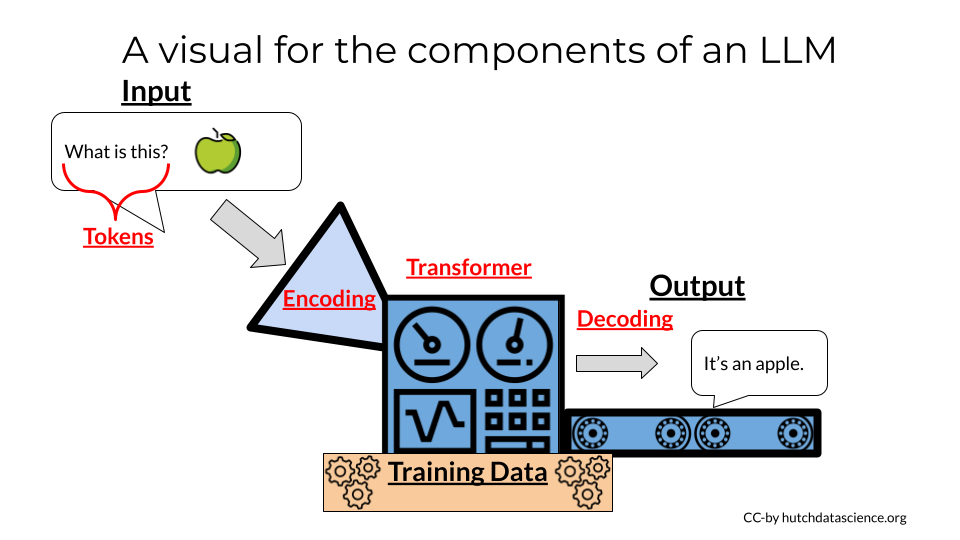
Large language models are one popular type of AI tool. So we can talk about the components of these models in the context of this visual. Tokens are units of a language (these might be words or phrases). Transformers are what organize tokens to find the meaning/context. Meanwhile to do this processing tokens are coded as Embeddings these are numerical representations of tokens. Encoders are what processes input text from a user. Meanwhile Decoders generate output text that is sent back to the user.
In summary:

One more important point about AI models. Their training and training data is critical. You have likely seen and heard about many biased things that large language models have said. This is because the language they were trained on – the language of human beings in our society – was also very biased.
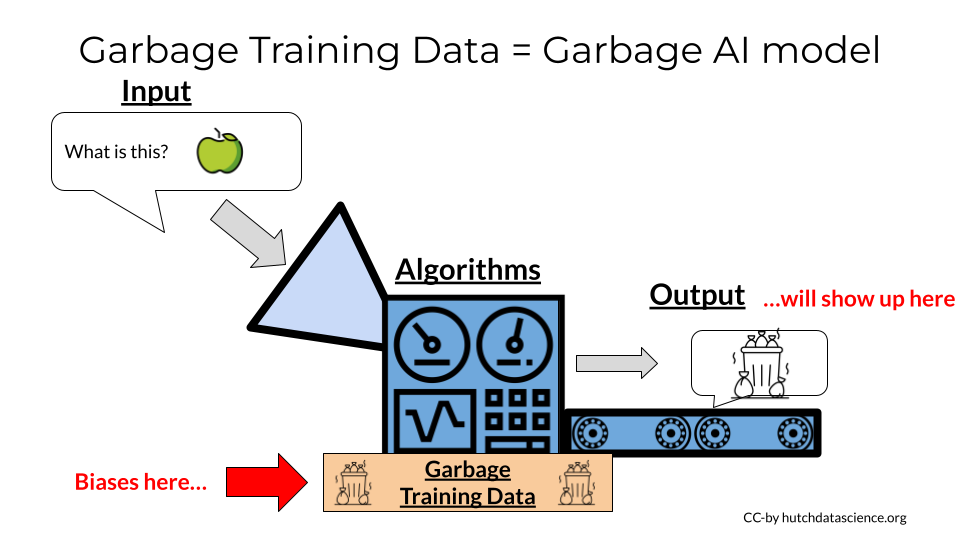
To summarize, for AI models can only be as good as their training. So garbage training data in means biased garbage as output.
–>