
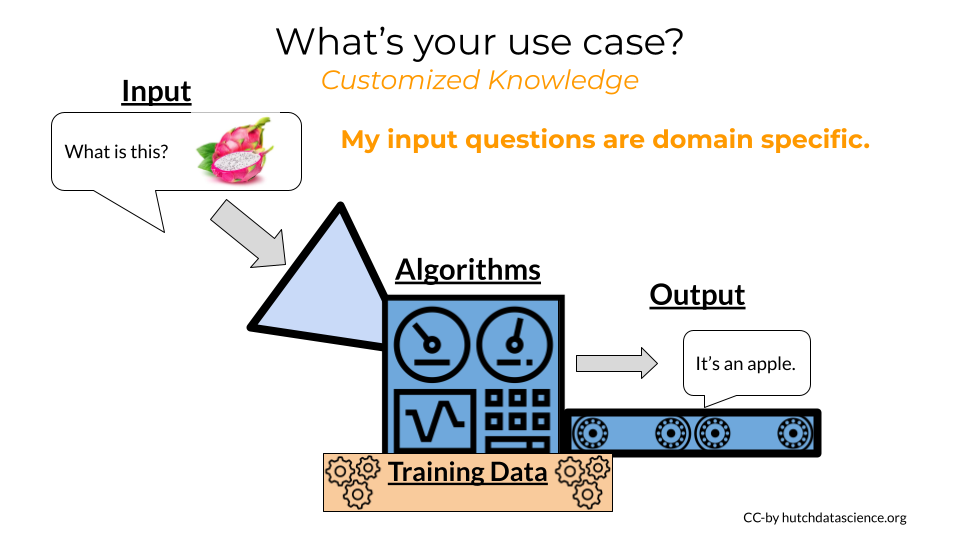
Customized Knowledge for AI
Disclaimer: The thoughts and ideas presented in this course are not to be substituted for legal or ethical advice and are only meant to give you a starting point for gathering information about AI policy and regulations to consider.
Learning objectives:
- Understand the motivation behind customized knowledge needs for AI tools
- Discuss a variety of low to high investment strategies for meeting customized knowledge needs
- Define and be able to contrast the differences between prompt engineering, promoting tuning, fine tuning, and training a model from scratch.
Intro
Customized knowledge needs are perhaps the most common AI tool need. And intuitively many can understand this. Just as you wouldn’t ask your primary physician to fix your motorbike, neither should you depend on an AI model for something it isn’t trained for.

When we are discussing customized knowledge needs, we are describing that existing AI models are not accurately addressing the needs we have. The output from the AI models is incorrect or not useful.
Summary of possible strategies
If the goal of customized knowledge is to get better output from an AI model, there are multiple strategies we can employ to achieve this goal. We will discuss them in order to lowest to highest investment. It’s generally best to see if the low investment strategies can meet your needs before turning to the higher investment strategies.
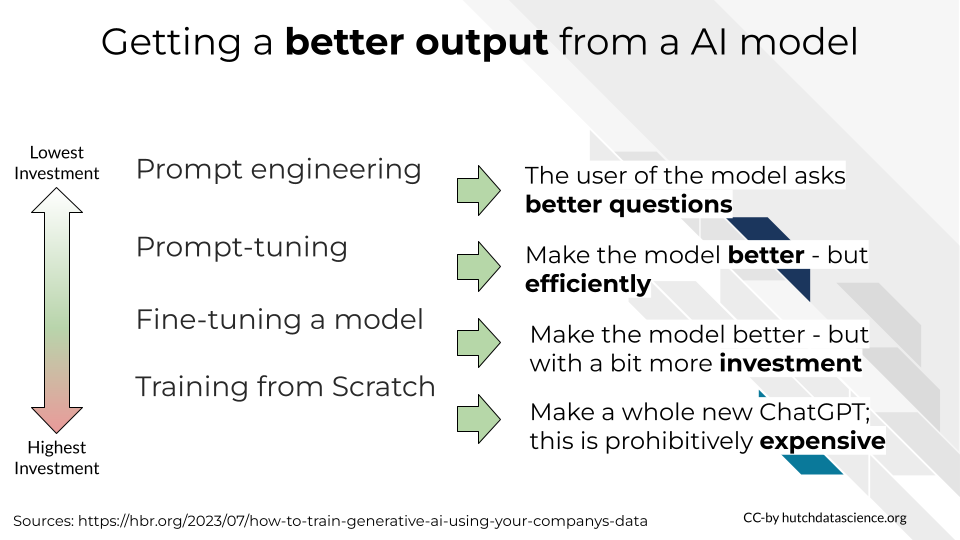
In summary, we will cover 4 different strategies for obtaining better output from an AI model.
- prompt engineering is when the user asks a better question as opposed to retraining the model.
- prompt tuning is when we use an iterative prompt and feedback strategy to make the model work better. It is lower investment attempt than fine tuning.
- fine tuning is when we give additional training to the model to have it perform better. So in our opening example, fine tuning is like sending the primary care fellowship to learn an additional skill set.
- training from scratch is when we quite literally build a whole new model from the beginning. For most use cases this is not necessary and it is prohibitively expensive.
Prompt engineering
Sometimes it’s not the model who needs training, it’s the user. AI models, just like humans, are not mind readers, and just as we all learned how to google, we also need to learn how to engineer prompts.

Best practices for prompt engineering according to Google
- Know the model’s strengths and weaknesses
- Be as specific as possible
- Utilize contextual prompts
- Provide AI models with examples
- Experiment with prompts and personas
- Try chain-of-thought prompting
In addition to prompt engineering it’s also vital to note that different AI models are trained on different things. So if one is not giving you the output you need, try another!
For LLMs, you can use https://poe.com/ or https://gpt.h2o.ai/ to test out prompts on multiple AI platforms side by side.

Prompt tuning or “P-tuning”
Because prompt tuning sounds a lot like prompt engineering it would be easy to think these strategies are the same, but they are not.
Prompt tuning is a lower stakes type of tuning where you use your prompts to help train an LLM. It’s more efficient than fine tuning. But it may or may not address your customization needs.
Basically you can think of prompt tuning like giving the LLM more context and instructions around what you are trying to receive back from it. A good analogy from this IBM article is that prompt tuning is like crossword puzzle clues for the LLM. It guides the model toward the right answer.

You can test out prompt tuning without doing software engineering by trying out the gpt.h2o platform

Fine Tuning
First some context around fine tuning.
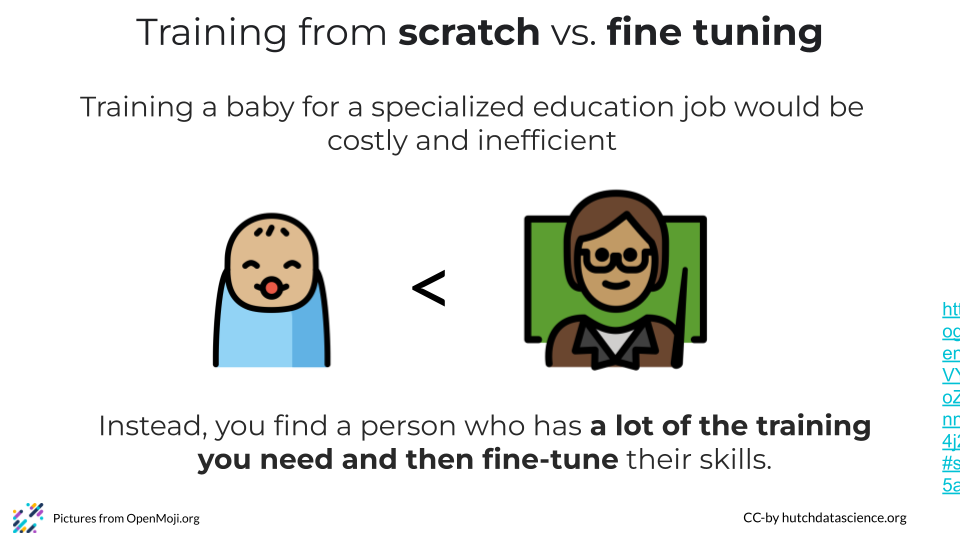
Let’s make a hiring analog. If you needed someone to fulfill a specialized education job, you wouldn’t train a baby who has almost no knowledge as a starting point. This would be unnecessarily time costly and inefficient. Instead, you find a person who has a lot of the training you need and then fine-tune their skills.

ChatGPT cost ~$100 million to create Training models from scratch requires an insane amount of data and computing costs It’s almost never where you will want to start.
So instead we will use the strategy of fine tuning. We aren’t going to create a model from scratch, instead we’re going to find one that has the training that most closely overlaps with our needs but we will provide them with additional training for our specific needs.
But fine tuning also might cost money, so before we jump to this strategy we need to check one more time whether we’ve surveyed the available models for their fitness of our project’s needs. Are you sure no other model works? if you’ve only tried ChatGPT go try other AI platforms. If an LLM is what you are looking for you can read our paper for a summary.

Find a base model to start with
For us to fine tune a model, we’ll first need to identify the base model that gets closest to what we are looking for.
When looking for a base model we want to consider at least these items congruently:
- Which is trained on data most similar to your application?
- Which models have performed the best based on your prior testing?
- No need to unnecessarily increase our computing costs, try to find the smallest one that performs the best. Note that bigger doesn’t mean it performs better – think jack of all trades master of none. You want a model that isn’t too general.

Speaking of the size of models, here is a visual demonstrating the sizes of a lot of the LLM’s in existence as of March 2023
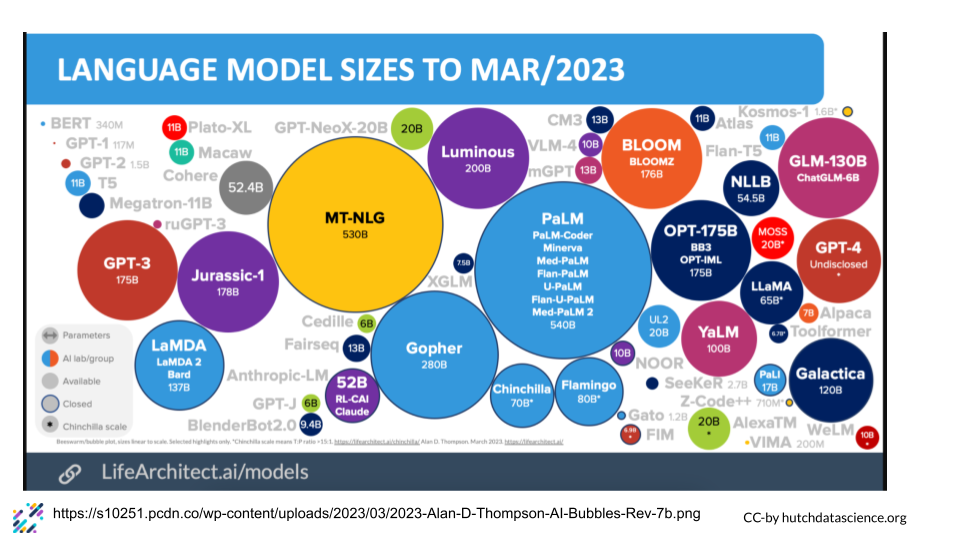
It also might be worth considering how these models are related. Perhaps an earlier, smaller version would be easier for you to train than using the latest, biggest large language model that doesn’t contain better information for your purposes.

Here’s places you can learn about AI models that are out there:
- This repository has a nice summary of a lot of currently available open source LLMs.
- Practical Guide to LLMs
- HuggingFace has all of the AI models - multimodal and more that we could want
Lastly, you should consider how you will evaluate the AI model’s performance? Where did the existing models you tried fall short?
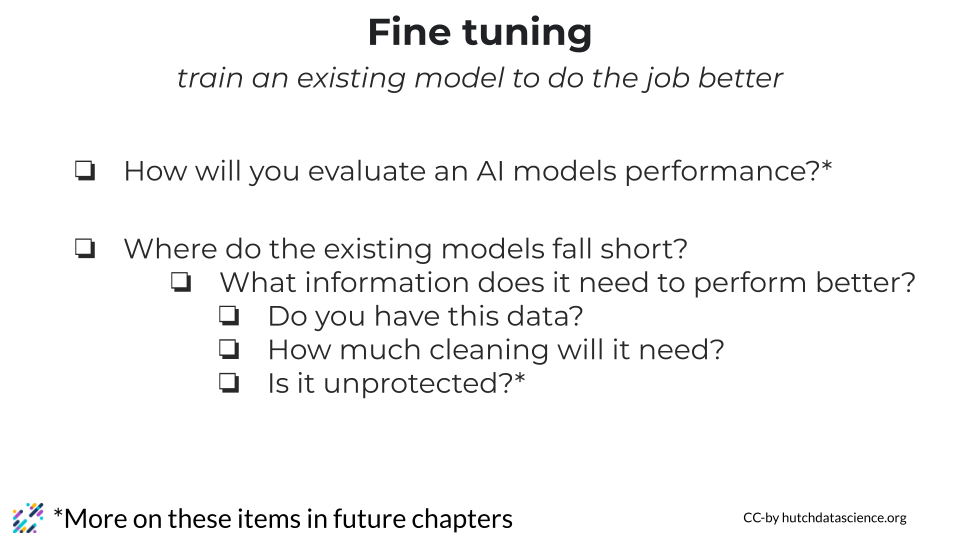
- What information do you think would help close the knowledge gap of the existing models to meet your needs?
- Do you have the data you might be able to fine tune a model to help it perform better?
- How much cleaning will this data need?
- Is this data unprotected and freely able to be shared or submitted to an open source repository?
We’ll discuss strategies for evaluation and data privacy in the upcoming chapters. But now is a good time to keep this in mind.
Example strategies for Fine tuning
Just because you may have identified you require fine tuning for an AI project doesn’t necessarily mean you will need a lot of technical expertise. There are some solutions like MonsterAPI and H2o that allow for fine tuning without code. These might be good platforms to explore either as a way to meet needs or to experiment to determine a larger strategy.

As described in the previous chapter, Hugging Face also has many tutorials on how to fine tune. This strategy would involve more code, frameworks, and software development.
If you do decide to build using open source models from Hugging Face or elsewhere you should consider these stages for your project timelines:
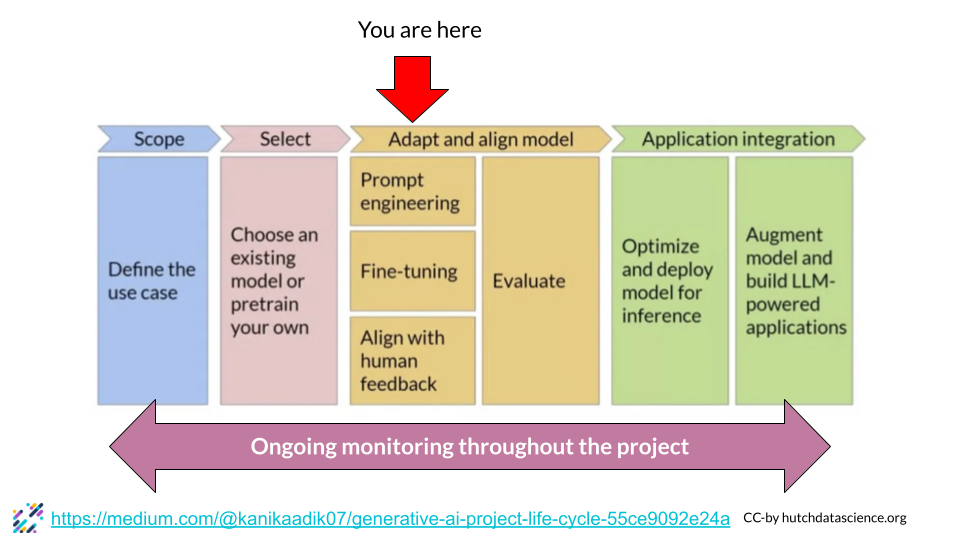
In this course we have already discuss defining the use case and selecting an existing model and adapting that model. But in the upcoming chapters we will discuss deployment and evaluation of models.
–>