
Adherence practices
Here we suggest some simple practices that can help you and others at your institution to better adhere to current proposed ethical guidelines.
- Start Slow - Starting slow can allow for time to better understand how AI systems work and any possible unexpected consequences.
- Check for Allowed Use - AI model responses are often not transparent about using code, text, images and other data types that may violate copyright. They are currently not necessarily trained to adequately credit those who contributed to the data that may help generate content.
- Use Multiple AI Tools - Using a variety of tools can help reduce the potential for ethical issues that may be specific to one tool, such as bias, misinformation, and security or privacy issues.
- Educate Yourself and Others - To actually comply with ethical standards, it is vital that users be educated about best practices for use. If you help set standards for an institution or group, it strongly advised that you carefully consider how to educate individuals about those standards of use.
Disclaimer: The thoughts and ideas presented in this course are not to be substituted for legal or ethical advice and are only meant to give you a starting point for gathering information about AI policy and regulations to consider.
Start Slow
Launching large projects using AI before you get a chance to test them could lead to disastrous consequences. Unforeseen challenges have already come up with many uses of AI, so it is wise to start small and do evaluation first before you roll out a system to more users.
This also gives you time to correspond with legal, equity, security, etc. experts about the risks of your AI use.

Tips for starting slow
For decision makers about AI users:
- Consider an early adopters program to evaluate usage.
- Educate early users about the limitations of AI.
- Consider using AI first for more specific purposes.
- Consult with experts about potential unforeseen challenges.
- Continue to assess and evaluate AI systems over time.
For decision makers about AI developers:
- Consider developing tools for more simple specific tasks, rather than broad difficult tasks.
- Consider giving potential users guidance about using the tool for simpler tasks at first.
- Continue to assess and evaluate AI systems over time.
Example 4 Real-World Example
IBM created Watson, an AI system that participated and won on the game show Jeopardy! and showed promise for advancing healthcare. However IBM had lofty goals for Watson to revolutionize cancer diagnosis, yet unexpected challenges resulted in unsafe and incorrect responses.
IBM poured many millions of dollars in the next few years into promoting Watson as a benevolent digital assistant that would help hospitals and farms as well as offices and factories. The challenges turned out to be far more difficult and time-consuming than anticipated. IBM insists that its revised A.I. strategy — a pared-down, less world-changing ambition — is working ((lohr_what_2021?)).
See here for addition info: https://ieeexplore.ieee.org/abstract/document/8678513
Check for Allowed Use
When AI systems are trained on data, they may also learn and incorporate copyrighted information or protected intellectual property. This means that AI-generated content could potentially infringe on the copyright or protection of trademarks or patents of the original author. For more extreme examples, if an AI system is trained on an essay or art or in some cases even code written by a human, the AI system could generate responses that are identical to or very similar to that of the original author, which some AI tools have done. Regardless, even training AI tools on copyrighted information where the responses are still relatively different, if the AI system uses this content without permission from the original author, this could constitute copyright or trademark infringement Brittain and Brittain (2023).

Example 5 Open AI is facing lawsuits about using writing from several authors to train ChatGPT without permission from the authors. While this poses legal questions, it also poses ethical questions about the use of these tools and what it means for the people who created content that helped train AI tools. How can we properly give credit to such individuals?
The lawsuits are summarized by Brittain and Brittain (2023):
The lawsuit is at least the third proposed copyright-infringement class action filed by authors against Microsoft-backed OpenAI. Companies, including Microsoft (MSFT.O), Meta Platforms (META.O) and Stability AI, have also been sued by copyright owners over the use of their work in AI training
The new San Francisco lawsuit said that works like books, plays and articles are particularly valuable for ChatGPT’s training as the “best examples of high-quality, long form writing.”
OpenAI and other companies have argued that AI training makes fair use of copyrighted material scraped from the internet.
The lawsuit requested an unspecified amount of money damages and an order blocking OpenAI’s “unlawful and unfair business practices.”
AI poses questions about how we define art and if AI will reduce the opportunities for employment for human artists. See here for an interesting discussion, in which it is argued that AI may enhance our capacity to create art. This will be an important topic for society to consider.
Tips for checking for allowed use
For decision makers about AI use:
- Be transparent about what AI tools you use to create content.
- Ask the AI tools if the content it helped generate used any content that you can cite.
Possible Generative AI Prompt: Did this content use any content from others that I can cite?
For decision makers about AI development:
- Obtain permission from the copyright holders of any content that you use to train an AI system. Only use content that has been licensed for use.
- Cite all content that you can.
Use Multiple AI Tools
Only using one AI tool can increase the risk of the ethical issues discussed. For example, it may be easier to determine if a tool incorrect about a response if we see that a variety of tools have different answers to the same prompt. Secondly, as our technology evolves, some tools may perform better than others at specific tasks. It is also necessary to check responses over time with the same tool, to verify that a result is even consistent from the same tool.

Tips for using multiple AI tools
For decision makers about AI use:
- Check that each tool you are using meets the privacy and security restrictions that you need.
- Utilize platforms that make it easier to use multiple AI tools, such as https://poe.com/, which as access to many tools, or Amazon Bedrock, which actually has a feature to send the same prompt to multiple tools automatically, including for more advanced usage in the development of models based on modifying existing foundation models.
- Evaluate the results of the same prompt multiple times with the same tool to see how consistent it is overtime.
- Use slightly different prompts to see how the response may change with the same tool.
- Consider if using tools that work with different types of data maybe helpful for answering the same question.
For decision makers about AI development:
- Consider if using different types of data maybe helpful for answering the same question.
- Consider promoting your tool on platforms that allow users to work with multiple AI tools.
Educate Yourself and Others
There are many studies indicating that individuals typically want to comply with ethical standards, but it becomes difficult when they do not know how (Giorgini et al. (2015)). Furthermore, individuals who receive training are much more likely to adhere to standards (Kowaleski, Sutherland, and Vetter (2019)).
Properly educating those you wish to comply with standards, can better ensure that compliance actually happens.
It is especially helpful if training materials are developed to be especially relevant to the actually potential uses by the individuals receiving training and if the training includes enough fundamentals so that individuals understand why policies are in place.

Example 6 Real-World Example
A lack of proper training at Samsung lead to a leak of proprietary data due to unauthorized use of ChatGPT by employees – see https://cybernews.com/news/chatgpt-samsung-data-leak for more details:
“The information employees shared with the chatbot supposedly included the source code of software responsible for measuring semiconductor equipment. A Samsung worker allegedly discovered an error in the code and queried ChatGPT for a solution.
OpenAI explicitly tells users not to share “any sensitive information in your conversations” in the company’s frequently asked questions (FAQ) section. Information that users directly provide to the chatbot is used to train the AI behind the bot.
Samsung supposedly discovered three attempts during which confidential data was revealed. Workers revealed restricted equipment data to the chatbot on two separate occasions and once sent the chatbot an excerpt from a corporate meeting. Privacy concerns over ChatGPT’s security have been ramping up since OpenAI revealed that a flaw in its bot exposed parts of conversations users had with it, as well as their payment details in some cases. As a result, the Italian Data Protection Authority has banned ChatGPT, while German lawmakers have said they could follow in Italy’s footsteps.”
Tips to educate yourself and others
For decision makers about AI use:
- Emphasize the importance of training and education.
- Recognize that general AI literacy to better understand how AI works, can help individuals use AI more responsibly.
- Seek existing education content made by experts that can possibly be modified for your use case.
- Consider how often people will need to be reminded about best practices. Should training be required regularly? Should individuals receive reminders about best practices especially in contexts in which they might use AI tools.
- Make your best practices easily findable and help point people to the right individuals to ask for guidance.
- Recognize that best practices for AI will likely change frequently in the near future as the technology evolves, education content should be updated accordingly.
For decision makers about AI development:
- Emphasize the importance of training and education.
- Recognize that more AI literacy to better understand security, privacy, bias, climate impact and more can help individuals develop AI more responsibly.
- Seek existing education content made by experts that can possibly be modified for your use case.
- Consider how often people will need to be reminded about best practices. Should training be required regularly? Should individuals receive reminders about best practices especially in contexts in which they might develop AI tools.
- Make your best practices easily findable and help point people to the right individuals to ask for guidance.
- Recognize that best practices for AI will likely change frequently in the near future as the technology evolves, education content should be updated accordingly.
We have also included an optional section for new developers about considerations for testing and training data to ensure accurate assessment of performance.
Effective use of Training and Testing data
In the previous chapters, we started to think about the ethics of using representative data for building our AI model. In this chapter we will see that even if our data is inclusive and represents our population of interest, issues can still happen if the data is mishandled during the AI model building process. Let’s take a look at how that can happen.
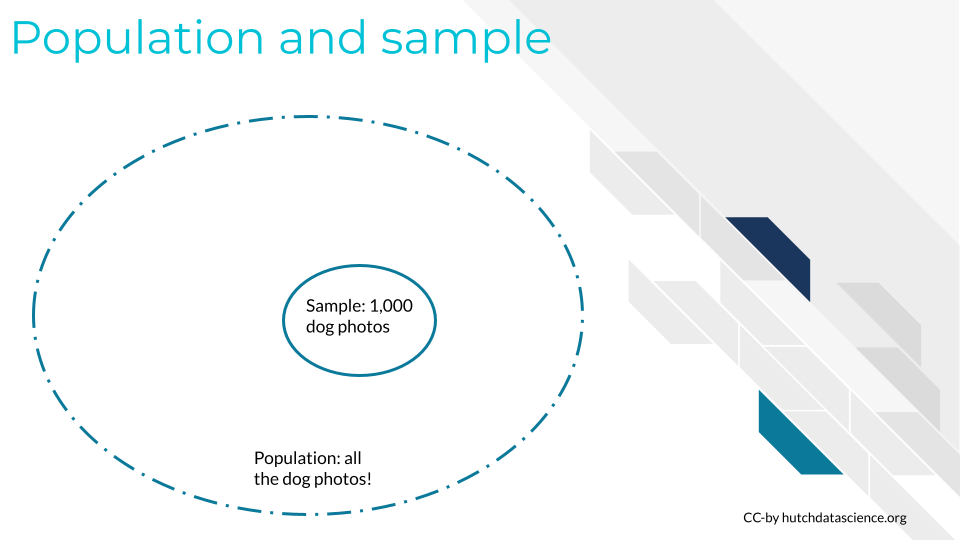
Population and sample
The data we collect to train our model is typically a limited representation of what we want to study, and as we explored in the previous chapter, bias can arise through our choice of selection. Let us define two terms commonly used in artificial intelligence and statistics: the population is the entire group of entities we want to get information from, study, and describe. If we were building an artificial intelligence system to classify dog photographs based on their breeds, then the population is every dog photograph in the world. That’s prohibitively expensive and not easy data to acquire, so we use a sample, which is a subset of the population, to represent our desired population.
Even if we are sure that the sample is representative of the population, a different type of bias, in this case statistical bias can arise. It has to do with how we use the sample data for training and evaluating the model. If we do this poorly, it can result in a model that gives skewed or inaccurate results at times, and/or we may overestimate the performance of the model. This statistical bias can also result in the other type of bias we have already described, in which a model unfairly impacts different people, often called unfairness.
There are many other sources of unfairness in model development - see Baker and Hawn (2022).
Training data

The above image depicts some of our samples for building an artificial intelligence model to classify dog photographs based on their breeds. Each dog photograph has a corresponding label that gives the correct dog breed, and the goal of the model training process is to have the artificial intelligence model learn the association between photograph and dog breed label. For now, we will use all of our samples for training the model. The data we use for model training is called the training data. Then, once the model is trained and has learned the association between photograph and dog breed, the model will be able make new predictions: given a new dog image without its breed label, the model will make a prediction of what its breed label is.
Testing data

To evaluate how well this model is good as predicting dog breeds from dog images, we need to use some of our samples to evaluate our model. The samples being used for model evaluation is called the testing data. For instance, suppose we used these four images to score our model. We give it to our trained model without the true breed label, and then the model makes a prediction on the breed. Then we compare the predicted breed label with the true label to compute the model accuracy.
Evaluation

Suppose we get 3 out of 4 breed predictions correct. That would be an accuracy of 75 percent.
Proper separation of Training and Testing data

However, we have inflated our model evaluation accuracy. The samples we used for model evaluation were also used for model training! Our training and testing data are not independent of each other. Why is this a problem? When we train a model, the model will naturally perform well on the training data, because the model has seen it before. This is called Overfitting. In real life, when the dog breed image labeling system is deployed, the model would not be seeing any dog images it has seen in the training data. Our model evaluation accuracy is likely too high because it is evaluated on data it was trained on.

Let’s fix this. Given a sample, we split it into two independent groups for training and testing. We use the training data for training the model, and we use the testing data for evaluating the model. They don’t overlap.

When we evaluate our model under this division of training and testing data, our accuracy will look a bit lower compared to our first scenario, but that is more realistic of what happens in the real world. Our model evaluation needs to be a simulation of what happens when we deploy our model into the real world!
Validation
Note that there should actually be an intermediate phase called validation, where we fine tune the model to be better at performing, in other words to improve the accuracy of predicting dog breeds, this should also ideally use a dataset that is independent from the training and testing set. You may also hear people use these two terms in a different order, where testing refers to the improvement phase and validation refers to the evaluation of the general performance of the model in other contexts.Sometimes the validation set for fine tuning is also called the development set. There are clever ways of taking advantage of more of the data for validation data, such as a method called “K-Fold cross validation”, in which many training and validation data subsets are trained and evaluated and for more validation and to determine if performance is consistent across more of the data. This is especially beneficial of there is diversity within the dataset, to better ensure that the data performs well on some of the rarer data points (for example, a more rare dog breed) (“Training, Validation, and Test Data Sets” (2023)).
Conclusions
This seemingly small tweak in how data is partitioned during model training and evaluation can have a large impact on how artificial intelligence systems are evaluated. We always should have independence between training and testing data so that our model accuracy is not inflated.
If we don’t have this independence of training and testing data, many real-life promotions of artificial intelligence efficacy may be exaggerated. Imagine that someone claimed that their cancer diagnostic model from a blood draw is 90%. But their testing data is a subset of their training data. That would over-inflate their model accuracy, and it will less accurate than advertised when used on new patient data. Doctors would make clinical decisions on inaccurate information and potentially create harm.
Summary
Here is a summary of all the tips we suggested:
- Disclose when you use AI tools to create content.
- Be aware that AI systems may behave in unexpected ways. Implement new AI solutions slowly to account for the unexpected. Test those systems and try to better understand how they work in different contexts.
- Adhere to restrictions for use of data and content created by AI systems where possible, citing the AI system itself and learning how the tool obtained permission for use can help reduce risk.
- Cross-check content from AI tools by using multiple AI tools and checking for consistent results over time. Check that each tool meets the privacy and security restrictions that you need.
- Emphasize training and education about AI and recognize that best practices will evolve as the technology evolves.
Overall, we hope that these suggestions will help us all use AI tools more responsibly. We recognize however, that as this is emerging technology and more ethical issues will emerge as we continue to use these tools in new ways. AI tools can even help us to use them more responsibly when we ask the right additional questions, but remember that human review is always necessary. Staying up-to-date on the current ethical considerations will also help us all continue to use AI responsibly.