
Chapter 3 Data Wrangling, Part 1
From our first two lessons, we are now equipped with enough fundamental programming skills to apply it to various steps in the data science workflow, which is a natural cycle that occurs in data analysis.

For the rest of the course, we focus on Transform and Visualize with the assumption that our data is in a nice, “Tidy format”. First, we need to understand what it means for a data to be “Tidy”.
3.1 Tidy Data
Here, we describe a standard of organizing data. It is important to have standards, as it facilitates a consistent way of thinking about data organization and building tools (functions) that make use of that standard. The principles of tidy data, developed by Hadley Wickham:
Each variable must have its own column.
Each observation must have its own row.
Each value must have its own cell.
If you want to be technical about what variables and observations are, Hadley Wickham describes:
A variable contains all values that measure the same underlying attribute (like height, temperature, duration) across units. An observation contains all values measured on the same unit (like a person, or a day, or a race) across attributes.

3.2 Our working Tidy Data: DepMap Project
The Dependency Map project is a multi-omics profiling of cancer cell lines combined with functional assays such as CRISPR and drug sensitivity to help identify cancer vulnerabilities and drug targets. Here are some of the data that we have public access to. We have been looking at the metadata since last session.
Metadata
Somatic mutations
Gene expression
Drug sensitivity
CRISPR knockout
and more…
Let’s load these datasets in, and see how these datasets fit the definition of Tidy data:
import pandas as pd
metadata = pd.read_csv("classroom_data/metadata.csv")
mutation = pd.read_csv("classroom_data/mutation.csv")
expression = pd.read_csv("classroom_data/expression.csv")## ModelID PatientID ... OncotreePrimaryDisease OncotreeLineage
## 0 ACH-000001 PT-gj46wT ... Ovarian Epithelial Tumor Ovary/Fallopian Tube
## 1 ACH-000002 PT-5qa3uk ... Acute Myeloid Leukemia Myeloid
## 2 ACH-000003 PT-puKIyc ... Colorectal Adenocarcinoma Bowel
## 3 ACH-000004 PT-q4K2cp ... Acute Myeloid Leukemia Myeloid
## 4 ACH-000005 PT-q4K2cp ... Acute Myeloid Leukemia Myeloid
##
## [5 rows x 30 columns]## ModelID CACNA1D_Mut CYP2D6_Mut ... CCDC28A_Mut C1orf194_Mut U2AF1_Mut
## 0 ACH-000001 False False ... False False False
## 1 ACH-000002 False False ... False False False
## 2 ACH-000004 False False ... False False False
## 3 ACH-000005 False False ... False False False
## 4 ACH-000006 False False ... False False False
##
## [5 rows x 540 columns]## ModelID ENPP4_Exp CREBBP_Exp ... OR5D13_Exp C2orf81_Exp OR8S1_Exp
## 0 ACH-001113 2.280956 4.094236 ... 0.0 1.726831 0.0
## 1 ACH-001289 3.622930 3.606442 ... 0.0 0.790772 0.0
## 2 ACH-001339 0.790772 2.970854 ... 0.0 0.575312 0.0
## 3 ACH-001538 3.485427 2.801159 ... 0.0 1.077243 0.0
## 4 ACH-000242 0.879706 3.327687 ... 0.0 0.722466 0.0
##
## [5 rows x 536 columns]| Dataframe | The observation is | Some variables are | Some values are |
|---|---|---|---|
| metadata | Cell line | ModelID, Age, OncotreeLineage | “ACH-000001”, 60, “Myeloid” |
| expression | Cell line | KRAS_Exp | 2.4, .3 |
| mutation | Cell line | KRAS_Mut | TRUE, FALSE |
3.3 Transform: “What do you want to do with this Dataframe”?
Remember that a major theme of the course is about: How we organize ideas <-> Instructing a computer to do something.
Until now, we haven’t focused too much on how we organize our scientific ideas to interact with what we can do with code. Let’s pivot to write our code driven by our scientific curiosity. After we are sure that we are working with Tidy data, we can ponder how we want to transform our data that satisfies our scientific question. We will look at several ways we can transform Tidy data, starting with subsetting columns and rows.
Here’s a starting prompt:
In the
metadatadataframe, which rows would you subset for and columns would you subset for that relate to a scientific question?
We have been using explicit subsetting with numerical indicies, such as “I want to filter for rows 20-50 and select columns 2 and 8”. We are now going to switch to implicit subsetting in which we describe the subsetting criteria via comparision operators and column names, such as:
“I want to subset for rows such that the OncotreeLineage is lung cancer and subset for columns Age and Sex.”
Notice that when we subset for rows in an implicit way, we formulate our criteria in terms of the columns. This is because we are guaranteed to have column names in Dataframes, but not row names.
3.3.0.1 Let’s convert our implicit subsetting criteria into code!
To subset for rows implicitly, we will use the conditional operators on Dataframe columns you used in Exercise 2. To formulate a conditional operator expression that OncotreeLineage is breast cancer:
## 0 False
## 1 False
## 2 False
## 3 False
## 4 False
## ...
## 1859 False
## 1860 False
## 1861 False
## 1862 False
## 1863 True
## Name: OncotreeLineage, Length: 1864, dtype: boolThen, we will use the .loc attribute (which is different than .iloc attribute!) and subsetting brackets to subset rows and columns Age and Sex at the same time:
## Age Sex
## 10 39.0 Female
## 13 44.0 Male
## 19 55.0 Female
## 27 39.0 Female
## 28 45.0 Male
## ... ... ...
## 1745 52.0 Male
## 1819 84.0 Male
## 1820 57.0 Female
## 1822 53.0 Male
## 1863 62.0 Male
##
## [241 rows x 2 columns]What’s going on here? The first component of the subset, metadata['OncotreeLineage'] == "Lung", subsets for the rows. It gives us a column of True and False values, and we keep rows that correspond to True values. Then, we specify the column names we want to subset for via a list.
Here’s another example:
df = pd.DataFrame(data={'status': ["treated", "untreated", "untreated", "discharged", "treated"],
'age_case': [25, 43, 21, 65, 7],
'age_control': [49, 20, 32, 25, 32]})
df## status age_case age_control
## 0 treated 25 49
## 1 untreated 43 20
## 2 untreated 21 32
## 3 discharged 65 25
## 4 treated 7 32“I want to subset for rows such that the status is”treated” and subset for columns status and age_case.”
## status age_case
## 0 treated 25
## 4 treated 7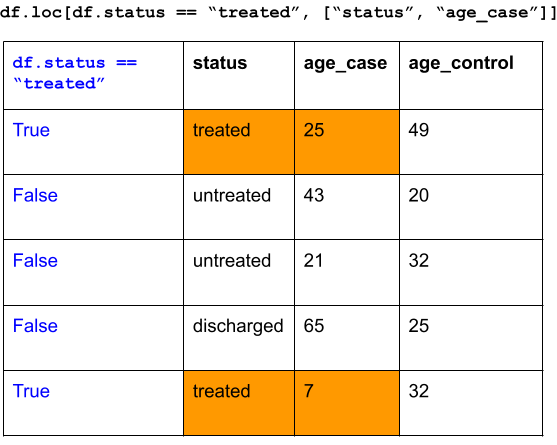
3.4 Summary Statistics
Now that your Dataframe has be transformed based on your scientific question, you can start doing some analysis on it! A common data science task is to examine summary statistics of a dataset, which summarizes the all the values from a variable in a numeric summary, such as mean, median, or mode.
If we look at the data structure of a Dataframe’s column, it is actually not a List, but an object called Series. It has methods can compute summary statistics for us. Let’s take a look at a few popular examples:
| Function method | What it takes in | What it does | Returns |
|---|---|---|---|
metadata.Age.mean() |
metadata.Age as a numeric Series |
Computes the mean value of the Age column. |
Float (NumPy) |
metadata['Age'].median() |
metadata['Age'] as a numeric Series |
Computes the median value of the Age column. |
Float (NumPy) |
metadata.Age.max() |
metadata.Age as a numeric Series |
Computes the max value of the Age column. |
Float (NumPy) |
metadata.OncotreeSubtype.value_counts() |
metadata.OncotreeSubtype as a string Series |
Creates a frequency table of all unique elements in OncotreeSubtype column. |
Series |
Let’s try it out, with some nice print formatting:
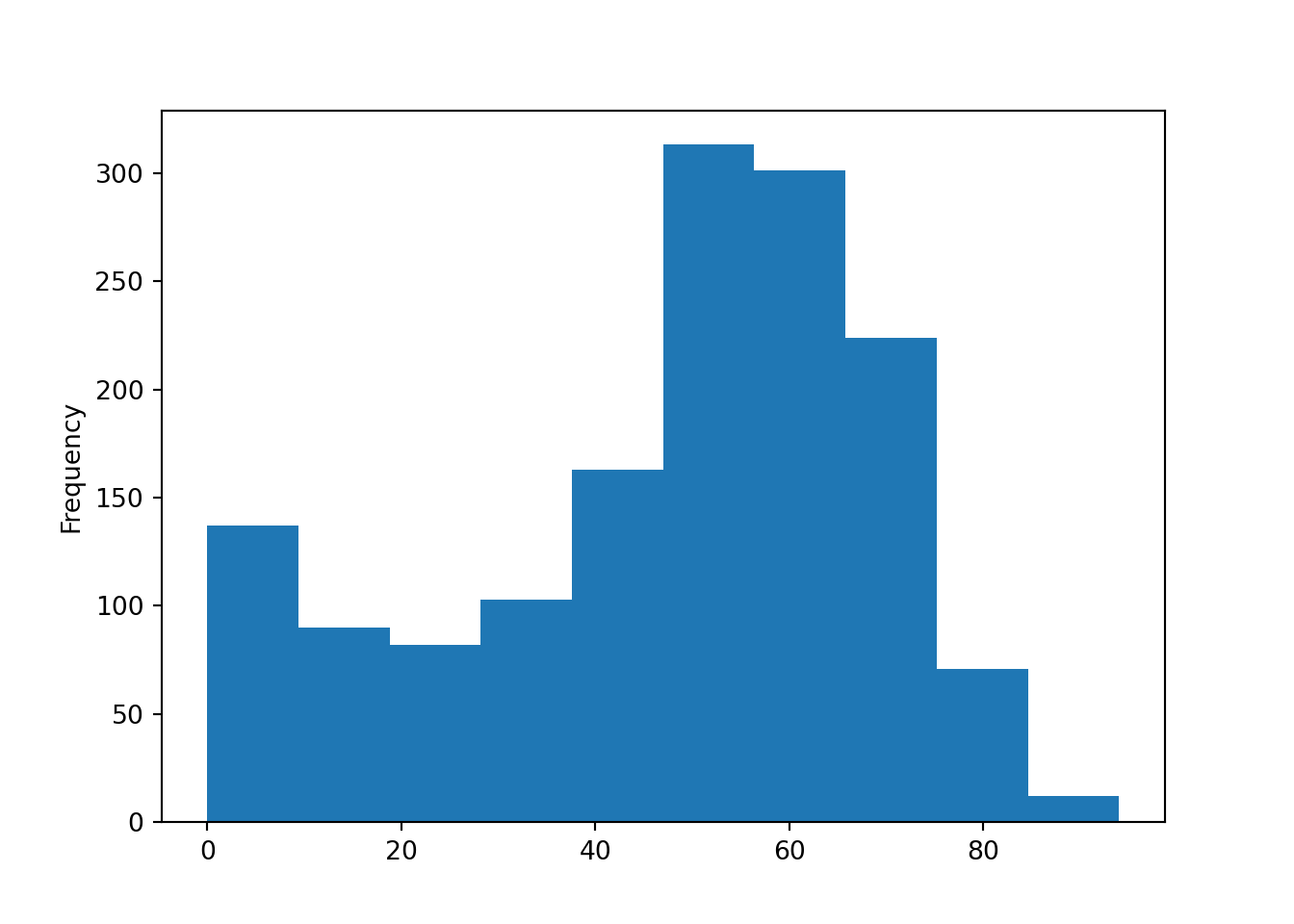
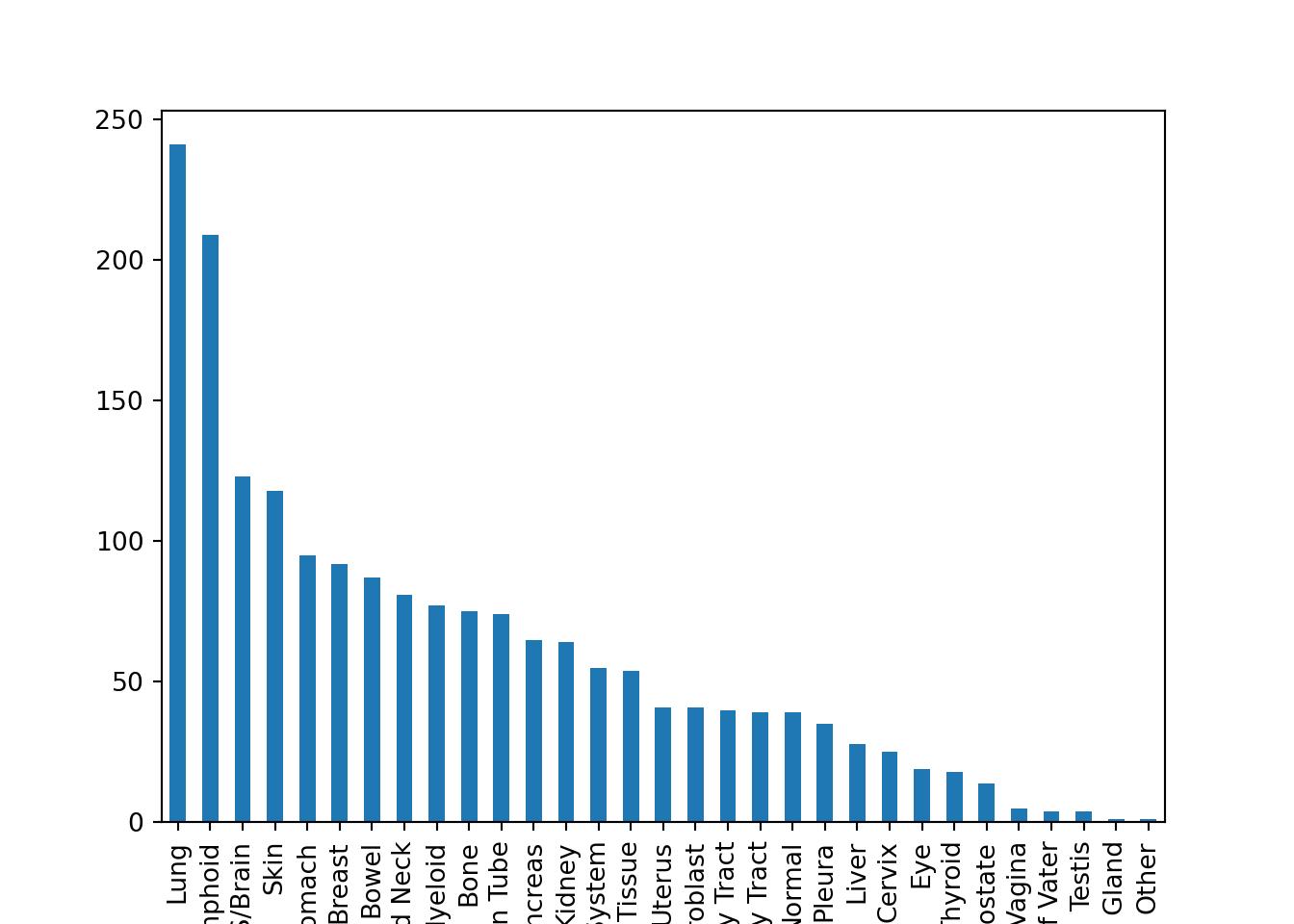
## Mean value of Age column: 47.45187165775401## Frequency of column OncotreeLineage
## Lung 241
## Lymphoid 209
## CNS/Brain 123
## Skin 118
## Esophagus/Stomach 95
## Breast 92
## Bowel 87
## Head and Neck 81
## Myeloid 77
## Bone 75
## Ovary/Fallopian Tube 74
## Pancreas 65
## Kidney 64
## Peripheral Nervous System 55
## Soft Tissue 54
## Uterus 41
## Fibroblast 41
## Biliary Tract 40
## Bladder/Urinary Tract 39
## Normal 39
## Pleura 35
## Liver 28
## Cervix 25
## Eye 19
## Thyroid 18
## Prostate 14
## Vulva/Vagina 5
## Ampulla of Vater 4
## Testis 4
## Adrenal Gland 1
## Other 1
## Name: count, dtype: int64Notice that the output of some of these methods are Float (NumPy). This refers to a Python Object called NumPy that is extremely popular for scientific computing, but we’re not focused on that in this course.)
3.5 Simple data visualization
We will dedicate extensive time later this course to talk about data visualization, but the Dataframe’s column, Series, has a method called .plot() that can help us make simple plots for one variable. The .plot() method will by default make a line plot, but it is not necessary the plot style we want, so we can give the optional argument kind a String value to specify the plot style. We use it for making a histogram or bar plot.
| Plot style | Useful for | kind = | Code |
|---|---|---|---|
| Histogram | Numerics | “hist” | metadata.Age.plot(kind = "hist") |
| Bar plot | Strings | “bar” | metadata.OncotreeSubtype.value_counts().plot(kind = "bar") |
Let’s look at a histogram:
Let’s look at a bar plot:
(The plt.figure() and plt.show() functions are used to render the plots on the website, but you don’t need to use it for your exercises. We will discuss this in more detail during our week of data visualization.)
3.5.0.1 Chained function calls
Let’s look at our bar plot syntax more carefully. We start with the column metadata.OncotreeLineage, and then we first use the method .value_counts() to get a Series of a frequency table. Then, we take the frequency table Series and use the .plot() method.
It is quite common in Python to have multiple “chained” function calls, in which the output of .value_counts() is used for the input of .plot() all in one line of code. It takes a bit of time to get used to this!
Here’s another example of a chained function call, which looks quite complex, but let’s break it down:
plt.figure()
metadata.loc[metadata.AgeCategory == "Adult", ].OncotreeLineage.value_counts().plot(kind="bar")
plt.show()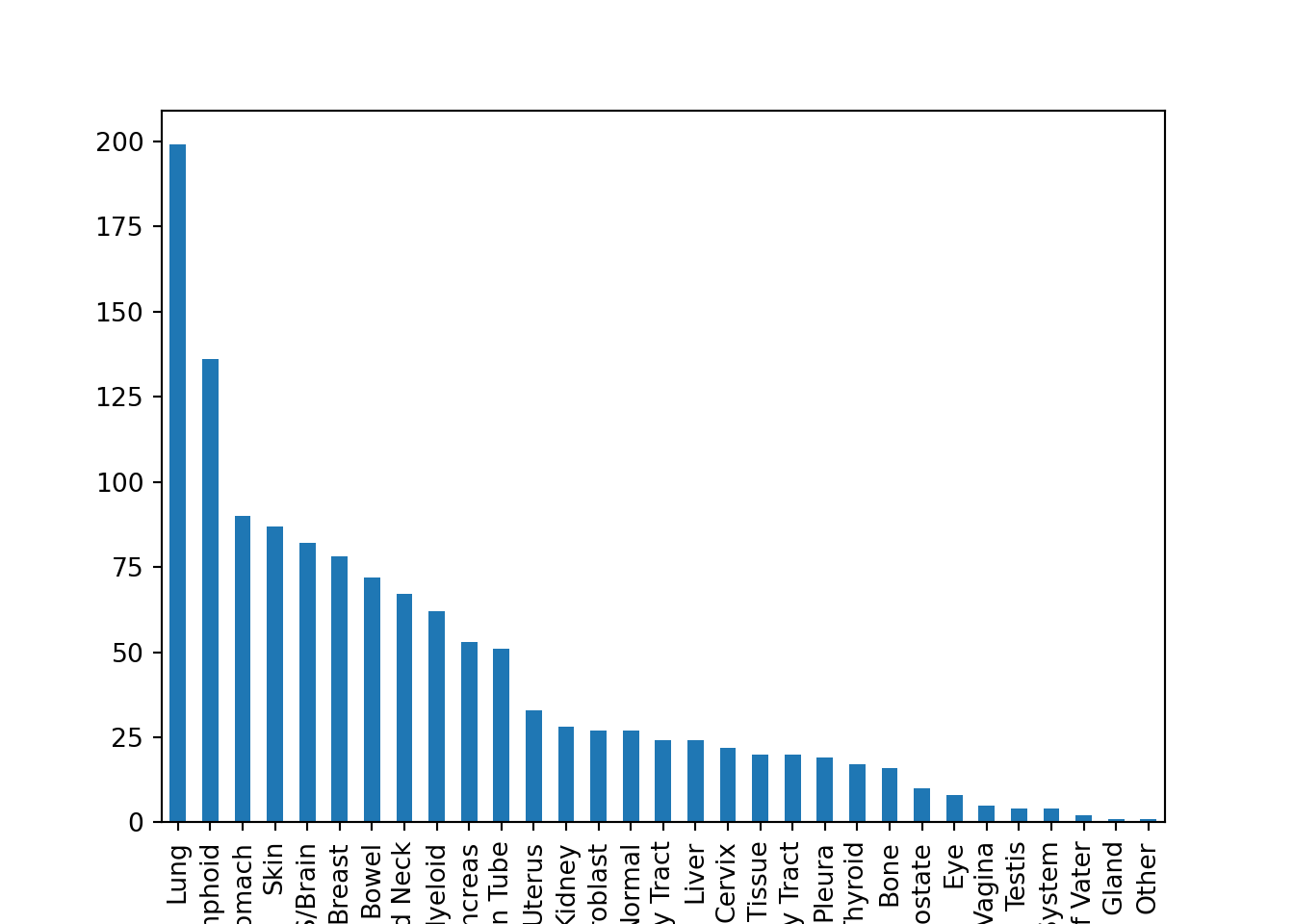
- We first take the entire
metadataand do some subsetting, which outputs a Dataframe. - We access the
OncotreeLineagecolumn, which outputs a Series. - We use the method
.value_counts(), which outputs a Series. - We make a plot out of it!
We could have, alternatively, done this in several lines of code:
plt.figure()
metadata_subset = metadata.loc[metadata.AgeCategory == "Adult", ]
metadata_subset_lineage = metadata_subset.OncotreeLineage
lineage_freq = metadata_subset_lineage.value_counts()
lineage_freq.plot(kind = "bar")
plt.show()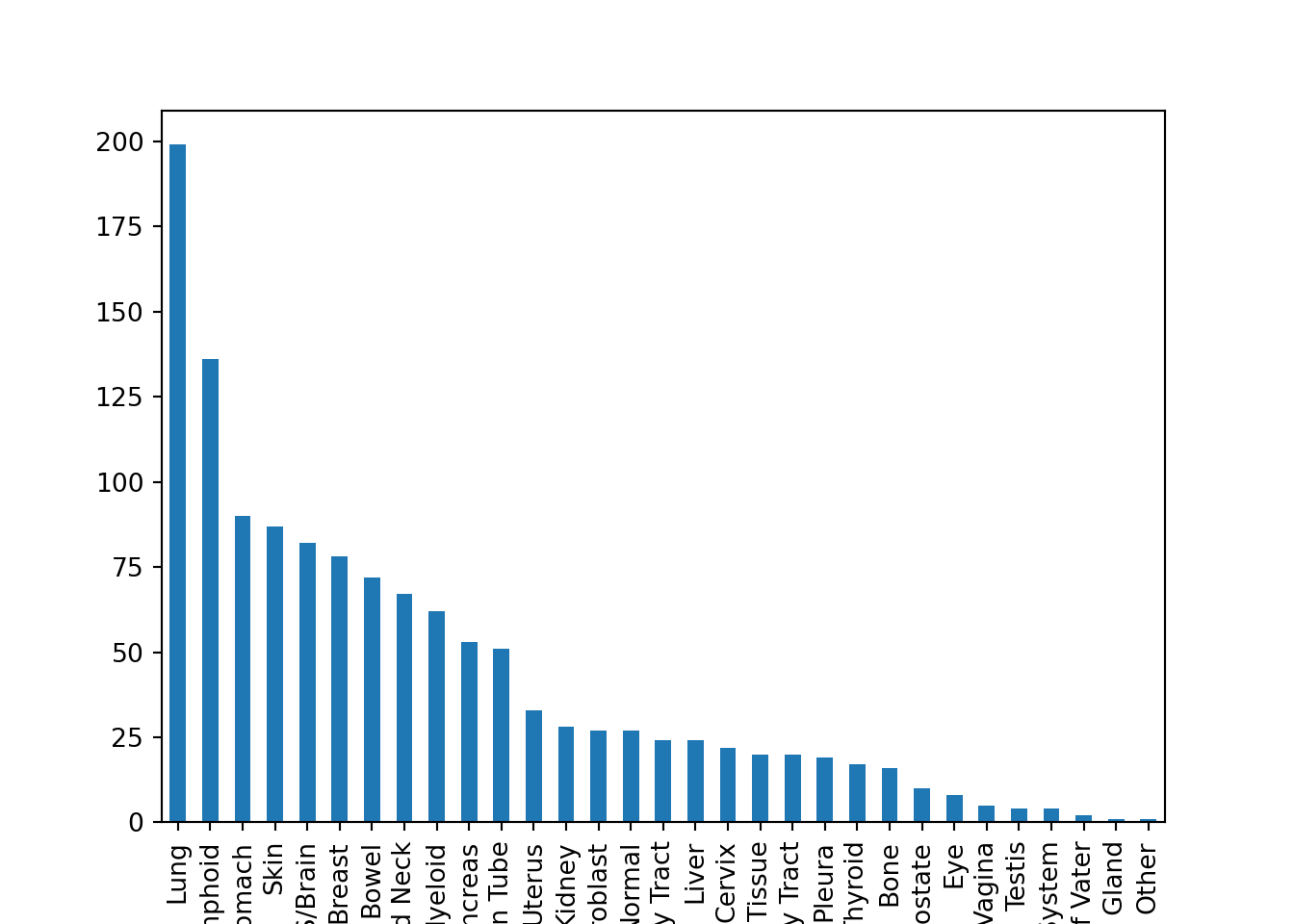
These are two different styles of code, but they do the exact same thing. It’s up to you to decide what is easier for you to understand.
3.6 Exercises
Exercise for week 3 can be found here.
