a = [1, 2, 3]
a.append(4)
print(a)[1, 2, 3, 4]Python organizes its objects in two ways: they can be mutable, or immutable. A mutable object can be modified after it has been defined, and an immutable object cannot be modified after it has been defined.
Examples of mutable data include: Lists,, Dictionaries, DataFrames, and Series. Examples of immutable data include: Tuples, and actually all the primitive data types, such as String, Integer, Float, Boolean. (If x = 3, then you can reassign x = 4, but you are not changing the actual value of 3.)
There are some interesting properties of mutable objects that we need to pay close attention to, in particular to assigning variables to each other.
In our style of writing code, we have been modifying our objects as we go, like this:
a = [1, 2, 3]
a.append(4)
print(a)[1, 2, 3, 4]However, consider the following pattern in which we assign b to a and then perform the append method on b.
a = [1, 2, 3]
b = a
b.append(4)
print(b)[1, 2, 3, 4]Let’s look at a also:
print(a)[1, 2, 3, 4]Strange, a was modified also! What’s going on?
When we created the variable a to equal the list [1, 2, 3], it is tempting to say, “the variable ‘a’ is a list with value [1, 2, 3]”, but that is technically incorrect!
The correct way: “the variable ‘a’ is a reference to a list with value [1, 2, 3]”.
We now make a distinction between the variable and the object: the variable gives the reference information to the object, and other variables can reference the same object also! When we evaluated b = a, we told b to reference thee same object as a, so modifying b modified a also.
This reference information tells us where the object is stored in the working memory of the computer, usually in the address form of a number.
Let’s see this in action:
If it doesn’t load properly, here is the link.
Here’s another illustration of the situation:
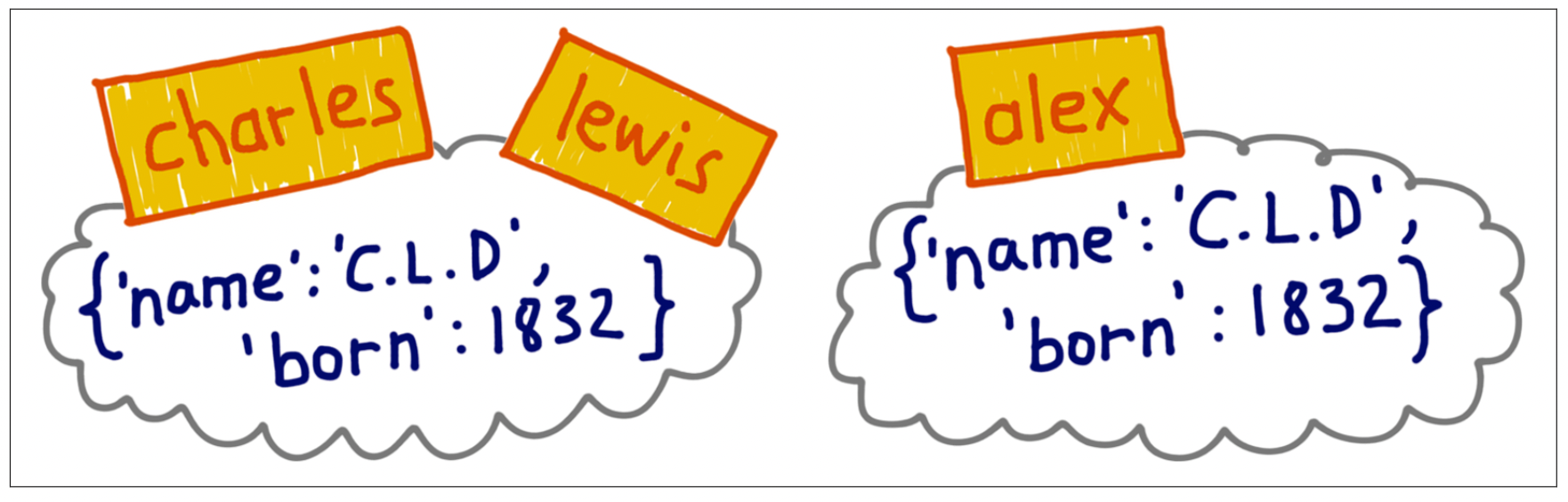
Sometimes, you want an actual copy of an object, not a reference to the object as we have seen before. Most objects have a .copy() method that will allow you to create a copy of it:
a = [1, 2, 3]
b = a.copy()
b.append(4)Now, a and b are distinct!
print("a:", a)
print("b:", b)a: [1, 2, 3]
b: [1, 2, 3, 4]If it doesn’t load properly, here is the link.
Here is how we use copy.deepcopy(x):
import copy
sub_list = ["apple", "pineapple"]
a = [sub_list, 1, 2]
b = copy.deepcopy(a)
b.append(3)
b[0].append("pear")
print("a:", a)
print("b:", b)a: [['apple', 'pineapple'], 1, 2]
b: [['apple', 'pineapple', 'pear'], 1, 2, 3]Let’s visualize what shallow deep copy looks like:
If it doesn’t load properly, here is the link.
When we work with Pandas Dataframes, variables are also assigned by reference: suppose we have a small dataframe simple_df:
import pandas as pd
import numpy as np
simple_df = pd.DataFrame(data={'id': ["AAA", "BBB", "CCC", "DDD", "EEE"],
'case_control': ["case", "case", "control", "control", "control"],
'measurement1': [2.5, 3.5, 9, .1, 2.2],
'measurement2': [0, 0, .5, .24, .003],
'measurement3': [80, 2, 1, 1, 2]})We assign analysis_df as simple_df, and log-transform the column “measurement1”, and see how it affects both dataframes:
analysis_df = simple_df
analysis_df.measurement1 = np.log(analysis_df.measurement1)
print(analysis_df) id case_control measurement1 measurement2 measurement3
0 AAA case 0.916291 0.000 80
1 BBB case 1.252763 0.000 2
2 CCC control 2.197225 0.500 1
3 DDD control -2.302585 0.240 1
4 EEE control 0.788457 0.003 2print(simple_df) id case_control measurement1 measurement2 measurement3
0 AAA case 0.916291 0.000 80
1 BBB case 1.252763 0.000 2
2 CCC control 2.197225 0.500 1
3 DDD control -2.302585 0.240 1
4 EEE control 0.788457 0.003 2To prevent this behavior, we can use the .copy() method:
simple_df = pd.DataFrame(data={'id': ["AAA", "BBB", "CCC", "DDD", "EEE"],
'case_control': ["case", "case", "control", "control", "control"],
'measurement1': [2.5, 3.5, 9, .1, 2.2],
'measurement2': [0, 0, .5, .24, .003],
'measurement3': [80, 2, 1, 1, 2]})
analysis_df = simple_df.copy()
analysis_df.measurement1 = np.log(analysis_df.measurement1)
print(analysis_df) id case_control measurement1 measurement2 measurement3
0 AAA case 0.916291 0.000 80
1 BBB case 1.252763 0.000 2
2 CCC control 2.197225 0.500 1
3 DDD control -2.302585 0.240 1
4 EEE control 0.788457 0.003 2So simple_df does not change:
print(simple_df) id case_control measurement1 measurement2 measurement3
0 AAA case 2.5 0.000 80
1 BBB case 3.5 0.000 2
2 CCC control 9.0 0.500 1
3 DDD control 0.1 0.240 1
4 EEE control 2.2 0.003 2However, some Dataframe operations and methods will automatically give you a copy, while others give you a reference.
For instance, when we subset via .loc, it returns a copy:
case_df = simple_df.loc[simple_df.case_control == "case"]
case_df.loc[:, 'measurement1'] = 5
print(case_df) id case_control measurement1 measurement2 measurement3
0 AAA case 5.0 0.0 80
1 BBB case 5.0 0.0 2print(simple_df) id case_control measurement1 measurement2 measurement3
0 AAA case 2.5 0.000 80
1 BBB case 3.5 0.000 2
2 CCC control 9.0 0.500 1
3 DDD control 0.1 0.240 1
4 EEE control 2.2 0.003 2However, if you subset to one specific column, it gives you a reference:
m1 = simple_df["measurement1"]
m1[0] = 5
print(m1)0 5.0
1 3.5
2 9.0
3 0.1
4 2.2
Name: measurement1, dtype: float64/tmp/ipykernel_387/1078013331.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
m1[0] = 5print(simple_df) id case_control measurement1 measurement2 measurement3
0 AAA case 5.0 0.000 80
1 BBB case 3.5 0.000 2
2 CCC control 9.0 0.500 1
3 DDD control 0.1 0.240 1
4 EEE control 2.2 0.003 2This pattern is called “Chained Assignment”, which means doing two bracket subsetting one after the other.
This behavior is super inconsistent and confusing, as it’s hard to predict when you will get a reference and when you get a copy. More details of this behavior can be found here. Future versions of Pandas Dataframe will remove these confusion, but for now, when you are modifying Dataframes, consider making a copy when you are unsure what its behaviors are when assigning variables to Dataframes.
Exercise for week 6 can be found here.