
Chapter 10 Refactoring Code
10.1 Learning Objectives
- Describe how refactoring code involves optimization for maintainability, efficiency, and reuse
- Explain why refactoring code is important for developers in the long-term
- Recognize the benefits and limitations of using AI tools to refactor code, as well as why AI tools are uniquely poised to be beneficial
- Implement prompt strategies that can be used to assist with refactoring code for correcting syntax, for adopting more consistent styling, for making code more concise, for making code easier to maintain, and for making code more efficient
10.2 Refactoring Basics
Code refactoring is the process of improving the quality of underlying code without changing its functionality. In other words, it’s a way of cleaning up and optimizing code so that it’s easier to maintain and more efficient. This often involves making small changes to the code, such as renaming variables or functions, reorganizing code blocks, or simplifying complex expressions. Refactoring is an essential practice in software development and helps to ensure that the codebase remains manageable and adaptable as requirements and business needs change over time.
Code refactoring helps to reduce technical debt, which is the accumulation of development work that needs to be done in the future as a result of taking shortcuts or using less than optimal solutions. Refactoring can help to identify potential issues and bugs before they cause problems, resulting in more stable software. Finally, refactoring code to be more readable and less verbose can create fewer headaches for you in the future.
To understand why code refactoring is important, imagine trying to cook in a disorganized and cluttered kitchen. You might be a fantastic cook, but you are spending more time searching for utensils and ingredients, and the quality of the meal could suffer as a result. Similarly, code that is disorganized and cluttered can be difficult to work with and can result in lower-quality software. Refactoring is like cleaning and organizing the kitchen - it makes the process of cooking (or coding) smoother and more efficient.

The information presented in this course is meant for use with open source code and software. It is unclear what happens to the information fed to AI chatbots as prompts, or how secure the data are. We know data are saved and may be used to further train the AI tools, but the specifics of how data are saved, as well as how sensitive or personally identifiable information are protected, is unknown.
Err on the side of caution when interacting with them. We do not recommend using proprietary code or private information for prompts unless you are working with an AI that you or your company built and you know is secure.
10.3 Example One: Correcting Syntax
Programming languages operate using their established set of rules. For example, Python uses indentation to define code blocks. However, when you shift between development environments, indentation and line breaks can sometimes be affected, causing major headaches!
Let’s say we run the following code:
def calculate_sum(a,b):
result = a + b
return result
def calculate_product(a,b):result = a * b
return result
def main():
a=5
b=6
sum_result = calculate_sum(a, b)
print("Sum:", sum_result)
product_result = calculate_product(a,b)
print("Product:", product_result)
if __name__ == '__main__':
main()## unexpected indent (<string>, line 3)We get the error above because our indentation is off. Let’s ask ChatGPT to clean things up.
Can you assist me with correcting the formatting and indentation issues in my Python code?
Of course! Here is the code after correcting the formatting and indentation:
def calculate_sum(a, b):
result = a + b
return result
def calculate_product(a, b):
result = a * b
return result
def main():
a = 5
b = 6
sum_result = calculate_sum(a, b)
print("Sum:", sum_result)
product_result = calculate_product(a, b)
print("Product:", product_result)
if __name__ == '__main__':
main()## Sum: 11
## Product: 30Much better! This can be quite handy when you can’t immediately see what is wrong with the formatting or if you are working with a large codebase.
10.4 Example Two: Styling and Convention
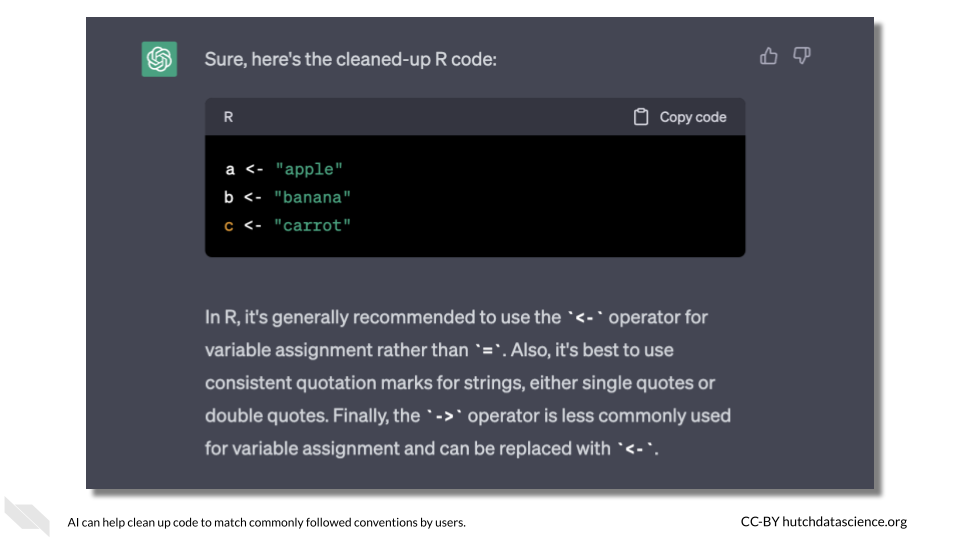
Sometimes programming languages have more flexible rules where there are multiple ways to take the same or almost the same action. For example, in the R programming language, there are several ways to perform variable assignment. However, is is generally accepted among R programmers that the <- operator should be used. Single and double quotes can be used for character types interchangeably, but it’s generally a good idea to stick with one or the other.
10.4.1 Commonly Accepted Convention
Let’s say we have the following code:
## [1] "apple" "banana" "carrot"This code does not produce any errors, but it doesn’t follow typical R convention. Let’s ask ChatGPT to clean things up.
Can you help me reformat my R code to follow accepted style conventions?
Much better! This code will now look more familiar to other R programmers.
10.4.2 Visual Styling
Some languages are flexible about line breaks, indentation, and spacing among code blocks. If you’re rapidly developing, things can get messy pretty quickly. Many development environments, for example RStudio and PyCharm, have the ability to format your code for you without changing any of the code itself. However, you can also get AI to do this according to your own preferences.
This code is pretty hard to read. Let’s see if AI can do better.
Can you space out this R code to make it more readable?
Sure! Here’s the same code with added spacing for improved readability:
Better! It’s easier to interpret because only one action is being taken on each step. By spacing out the code and breaking it into multiple lines, it becomes easier for the human eye to scan for structure, logic, errors, and/or inconsistencies.
10.5 Example Three: Staying DRY
The DRY (Don’t Repeat Yourself) programming tenet is essential to good software. By avoiding repetition in code, we can reduce the amount of duplicate code we need to write and maintain. If we need to change the functionality of a certain piece of code, we have to make the same change in multiple places, which can be time-consuming and error-prone.
Let’s take the following Python code:
def print_greetings():
print("Hello, Alice!")
print("Hello, Bob!")
print("Hello, Carol!")
print("Hello, David!")
print("Hello, Eve!")
print_greetings()## Hello, Alice!
## Hello, Bob!
## Hello, Carol!
## Hello, David!
## Hello, Eve!Notice how repetitive this code is? print() and the string "Hello, " appear five times. We can improve this!
Could you please refactor my Python code to make it more DRY?
Sure, here’s a refactored version of your code:
def print_greeting(name):
print(f"Hello, {name}!")
def print_greetings():
names = ["Alice", "Bob", "Carol", "David", "Eve"]
for name in names:
print_greeting(name)
print_greetings()## Hello, Alice!
## Hello, Bob!
## Hello, Carol!
## Hello, David!
## Hello, Eve!Now let’s imagine your software lead has asked us to change the greeting to Spanish. Notice how we only have to change the second line of code:
def print_greeting(name):
print(f"¡Hola, {name}!")
def print_greetings():
names = ["Alice", "Bob", "Carol", "David", "Eve"]
for name in names:
print_greeting(name)
print_greetings()## ¡Hola, Alice!
## ¡Hola, Bob!
## ¡Hola, Carol!
## ¡Hola, David!
## ¡Hola, Eve!Much easier.
10.6 Example Four: Keeping Code Alive
During software development, code is often changing rapidly. It’s common to end up with functions or variables you don’t need anymore. It’s best practice to remove “dead” code from your codebase: it’s distracting and can make maintenance more challenging. Programmers should resist the urge to hang on to unused code in the expectation that they might need it one day. Version control, such as provided by git and GitHub, let you keep a record of old code without cluttering your final version.
Let’s take a look at some Python code with some dead code:
def default_values():
a = 5
b = 6
return a, b
def calculate_sum(a, b):
result = a + b
return result
def calculate_product(x, y):
return x * y
def simulate_data():
a, b = default_values()
dat = calculate_sum(a, b) + calculate_sum(a, b)
return dat
def main():
a = 5
b = 6
a, b = default_values()
sum_result = calculate_sum(a, b)
print("Sum:", sum_result)
if __name__ == '__main__':
main()## Sum: 11Some of these functions aren’t used in the final step, typically defined in python as the main() function. Let’s ask AI to remove them.
I need help with eliminating unused functions in my Python script.
Sure! Here’s a refactored version:
def default_values():
a = 5
b = 6
return a, b
def calculate_sum(a, b):
result = a + b
return result
def main():
a = 5
b = 6
a, b = default_values()
sum_result = calculate_sum(a, b)
print("Sum:", sum_result)
if __name__ == '__main__':
main()## Sum: 11Great! Now our code is much more manageable. This code only includes the necessary functions needed to run the main() function. We can go a step further!
Can you help me refactor my python code to make it more concise?
Certainly! Here’s a more concise version of your code:
def calculate_sum(a=5, b=6):
return a + b
def main():
sum_result = calculate_sum()
print("Sum:", sum_result)
if __name__ == '__main__':
main()## Sum: 11In this version, the calculate_sum function is simplified to take default arguments for a and b. This means the default_values function is no longer necessary. The a and b variables are also removed from main, as they are no longer needed. Much better and easier to look at overall.
10.7 Example Five: Making Code Readable
Usually, our first goal as programmers is to get the response we need from the code. Readability might be the last thing on our minds. Luckily, AI can help with this. Let’s imagine we whipped up this code pretty quickly. It is tough to read, and it could definitely be improved.
for(term in c("good","bad","ugly")){
print(c(rep(term,3),paste("really",stringr::str_to_upper(term))))
}## [1] "good" "good" "good" "really GOOD"
## [1] "bad" "bad" "bad" "really BAD"
## [1] "ugly" "ugly" "ugly" "really UGLY"Let’s see if AI can do better.
Can you help me clean up this R code so it is more readable?
Sure! Here’s a more readable version of the code:
library(stringr)
for(term in c("good", "bad", "ugly")) {
print(c(rep(term, 3), paste("really", str_to_upper(term))))
}## [1] "good" "good" "good" "really GOOD"
## [1] "bad" "bad" "bad" "really BAD"
## [1] "ugly" "ugly" "ugly" "really UGLY"I added whitespace around operators and after commas for better readability. I also loaded the stringr package explicitly using library() to make the code more self-contained.
This is a good start, but not much has changed. Let’s try again. On ChatGPT, we can click “Regenerate Response”.
Here’s a cleaned-up version of the R code that is more readable:
library(stringr)
terms <- c("good", "bad", "ugly")
for (term in terms) {
rep_term <- rep(term, 3)
upper_term <- str_to_upper(term)
really_upper_term <- paste("really", upper_term)
result <- c(rep_term, really_upper_term)
print(result)
}## [1] "good" "good" "good" "really GOOD"
## [1] "bad" "bad" "bad" "really BAD"
## [1] "ugly" "ugly" "ugly" "really UGLY"I’ve stored the repeated term and the uppercased term in separate variables to make the code more readable. I’ve also separated the construction of the “really” phrase from the uppercased term to make it clearer what’s happening. Finally, I’ve used whitespace and indentation to make the structure of the code more apparent.
Better! While the code takes up a greater number of lines, it’s easier to interpret because only one action is being taken on each step.
10.8 Example Six: Keep it Brief
As we learned above, following the DRY principle and removing dead code can make your code easier to interpret, maintain, and debug. However, sometimes the issue is the functions themselves. No one has perfect knowledge of everything in their programming language. AI can help us determine if there are any more efficient sets of functions that do the same thing. Here is some code that plays with the “CO2” dataset in R:
library(datasets)
for (type in unique(CO2$Type)) {
dat_subset <- CO2[CO2$Type == type, ]
for (plant in unique(dat_subset$Plant)) {
dat_subset_2 <- dat_subset[dat_subset$Plant == plant, ]
print(paste(dat_subset_2$Plant[1], round(mean(dat_subset_2$uptake), 1)))
}
}## [1] "Qn1 33.2"
## [1] "Qn2 35.2"
## [1] "Qn3 37.6"
## [1] "Qc1 30"
## [1] "Qc2 32.7"
## [1] "Qc3 32.6"
## [1] "Mn1 26.4"
## [1] "Mn2 27.3"
## [1] "Mn3 24.1"
## [1] "Mc1 18"
## [1] "Mc2 12.1"
## [1] "Mc3 17.3"Let’s see if AI has any ideas for making it more concise.
Can you make this code more concise?
Here’s a more concise version using dplyr package in R:
## # A tibble: 12 × 3
## # Groups: Type [2]
## Type Plant mean_uptake
## <fct> <ord> <dbl>
## 1 Quebec Qn1 33.2
## 2 Quebec Qn2 35.2
## 3 Quebec Qn3 37.6
## 4 Quebec Qc1 30.0
## 5 Quebec Qc3 32.6
## 6 Quebec Qc2 32.7
## 7 Mississippi Mn3 24.1
## 8 Mississippi Mn2 27.3
## 9 Mississippi Mn1 26.4
## 10 Mississippi Mc2 12.1
## 11 Mississippi Mc3 17.3
## 12 Mississippi Mc1 18This code groups the CO2 dataset by Type and Plant, calculates the mean uptake for each group using summarize, and then prints the resulting data frame. The code is shorter and more concise because it uses the dplyr package, which has built-in functions for data manipulation and summarization.
Refactoring the code to be more concise using dplyr makes it easier to read and understand the steps involved in the data manipulation. It also reduces the number of nested loops and intermediate variables, making the code more efficient and reducing the chance of errors. Ultimately, it is your job as a programmer to use your best judgment on the fine balance between brevity and readability, as the best solution is not always this obvious.
Remember that you can regenerate the AI’s response if you want more options.
10.9 Code optimization
Sometimes time and efficiency is of the essence. Loops can be slow and time consuming in many languages. Take for example the following R code that calculates the cross product between two vectors x and y using nested for loops:
set.seed(123)
n <- 10000
x <- rnorm(n)
y <- rnorm(n)
z <- numeric(n)
# Start timer
start_time <- proc.time()
for(i in 1:n) {
for(j in 1:n) {
z[i] <- z[i] + x[i]*y[j]
}
}
# End timer
proc.time() - start_time## user system elapsed
## 8.331 0.001 8.331What is a faster, more optimized way of running the following R code?
set.seed(123)
n <- 10000
x <- rnorm(n)
y <- rnorm(n)
# Start timer
start_time <- proc.time()
z <- outer(x, y, "*")
z <- rowSums(z)
# End timer
proc.time() - start_time## user system elapsed
## 0.757 0.589 0.652The outer() function performs the same calculation as the nested loop in the original code, but more efficiently. It returns a matrix of all possible combinations of x and y values, with each element of the matrix being the product of the corresponding x and y values. The rowSums() function is then used to sum the elements of each row of the matrix, which is equivalent to summing the products of x and y for each index i in the original loop. This method avoids the need for the nested loop, resulting in a faster and more efficient computation.
So much faster! We can look at another option by regenerating the response:
set.seed(123)
n <- 10000
x <- rnorm(n)
y <- rnorm(n)
z <- numeric(n)
# Start timer
start_time <- proc.time()
z <- x %*% t(y)
# End timer
proc.time() - start_time## user system elapsed
## 0.197 0.331 0.137One optimized way to perform the same calculation is by using the %*% operator to perform matrix multiplication. This can be done by converting x and y to matrices and transposing one of them so that their dimensions align for matrix multiplication. This code should be much faster than the original implementation because it takes advantage of highly optimized matrix multiplication algorithms in R.
While this second suggestion is faster, you will need to consider what aspects of the codebase are most important in each instance. For example, this code runs more quickly, but the %*% operator might be unfamiliar to some R programmers. In cases where efficiency is less important, or the data are not large, you might consider maximizing readability.
10.10 Challenges and Limitations
Like humans, AI can make mistakes. Be sure to keep the following in mind as you use AI to refactor your code.
10.10.1 Complexity
Refactoring is often a complex process that requires deep understanding of the code and its context. AI may not always be able to fully understand the complexity of the code and may struggle to identify the best refactoring strategy. Use a modular approach whenever possible.
10.10.2 Limited Data
AI models require large amounts of data to learn from, but in the case of code refactoring, there is often limited data available. This can make it difficult for AI models to generalize to new code bases and situations, especially if you are using a more niche programming language.
10.10.3 Quality Control
Automated refactoring tools that use AI may not always produce code that is of the same quality as code produced by human developers. It can be difficult to always ensure that the refactored code is maintainable, efficient, and free of bugs. You need to use your best judgment when copying and pasting AI-produced code into your codebase.
You should always include unit tests in your code. Tests can help you catch bugs, including those introduced accidentally by AI.
Because AI models are created by humans, they can be biased. This means they may not always identify your preferred refactorings or may prioritize certain types of refactorings over others. In some cases, this can lead to suboptimal code quality and may create technical debt over time.
10.10.4 Security
When using AI to refactor code, the code itself is often sent to an external service or platform for analysis and transformation. This can raise concerns about the security of the code, especially if it contains sensitive information such as trade secrets, proprietary algorithms, or personal data. If your code is sensitive, it’s important to carefully vet any third-party AI tools or services used in the refactoring process.
