In our linear and logistic regression models, we have always made the assumption that the number of predictors is less than the number of samples. However, that is not always true in the high-dimensionalproblems. This is when the number of predictors is greater than the number of samples analyzed. How could this be? Consider the following examples:
In molecular biology, high-throughput sequencing technologies can make thousands of measurements across a human genome at once, for a single sample. For instance, bulk RNA-seq can in theory measure 20,000 different gene expressions of a sample.
In computer vision, if each sample is an image, then one can derive a vast amount of measurements from an image. Each pixel could be a single measurement, or some defined feature of the image, such as the presence of a face or a cat. One can imagine gathering thousands of measurements from a image.
In Natural Language Processing (NLP), a document can be treated as a sample. A document consists of a large number of words, and one can derive measurements from single words, or a collection of words, such as themes or writing style. The number of measurements can be vast and large.
In mathematical form, we say we have a high dimensional problem when \(p\) , the number of predictors, is large relative to the number of samples:
If we try to run linear or logistic regression in a high-dimensional problem, it will not work, due to the mathematical limits of these tools.
What people typically do in light of a high-dimensional problem is to use a dimensional reduction method, to reduce the number of features lower than the number of samples in the analysis. We will explore two methods today: regularization methods and principal components analysis.
6.1 Challenges of high dimension regression
Most predictors in the model can be written as a combination of other predictors, so the problem of predictors correlated to each other is present everywhere.
Therefore, we can never identify the best predictors of the outcome, only one of of many possible models to consider. The response can also be written as a combination of other predictors too.
Predictor-response plots will not tell the whole story, due to projecting down too many dimensions.
Most statistics of fit that are used in low-dimensional regression, such as p-values, \(R^2\), AIC, BIC on the training dataset does not work at the high dimensional setting.
Our diagnostics plots are not feasible to scale to many dimensions, so they are generally not used in practice.
6.2Regularization methods
Regularization methods will let us fit all the predictors in a model, and in the process of creating the model, it will naturally encourage some of the parameter estimates to be zero. This is an example of dimension reduction. The resulting model will have less predictors than samples. The best known regularization techniques are called ridgeregression and lasso regression. For this class, we will use lasso regression, and you can read in the appendix the difference between the two methods.
Recall that in linear regression, we fit a line where the Mean Squared Error (MSE) is minimized. In regularization methods, the quantity we try to minimize for the model includes additional terms:
\[
minimize(MSE + \lambda \cdot Parameters)
\]
What is going on here?
When \(MSE\) is minimized, the model gives the shortest distance to the data points, just like we did in linear regression.
When the \(Parameters\) are minimized (such as \(\beta_1, … \beta_p\)), it reduces the magnitude of the parameters towards zero. This reduces the number of predictors being used in the final model, performing dimension reduction.
The tuning parameter (sometimes called hyperparameter) \(\lambda\) (“lambda”) serves to control the balance between minimizing the \(MSE\) vs. minimizing the \(Parameters\). When \(\lambda=0\), we just have to minimize the \(MSE\), ie. linear regression. When \(\lambda\) is large, then we start to minimize \(Parameters\) more and encourages some of the parameter estimates to be zero. Selecting the appropriate \(\lambda\) is important in the model training process, and we will see how to do that via Cross-Validation.
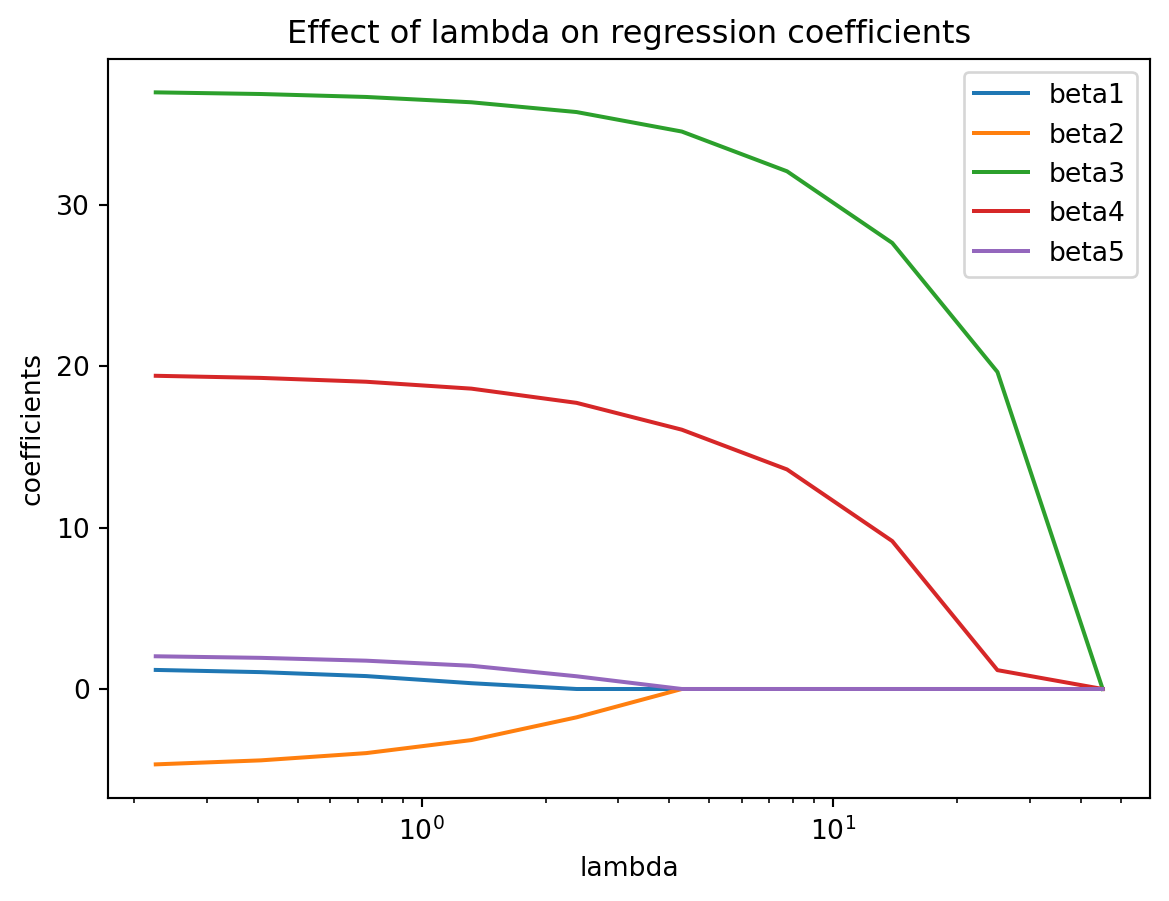
Let’s see an example of the effect of \(\lambda\) on a model with 5 predictors, parameter weights \(\beta_1\)… \(\beta_5\).
import pandas as pdimport seaborn as snsimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_diabetesfrom sklearn.linear_model import LassoCV, lasso_path, LinearRegressionX, y = load_diabetes(return_X_y=True)X = X[:, :5]X /= X.std(axis=0)alphas_lasso, coefs_lasso, _ = lasso_path(X, y, n_alphas=10, eps=5e-3)plt.clf()for i, coef_lasso inenumerate(coefs_lasso): plt.semilogx(alphas_lasso, coef_lasso, label='beta'+str(i+1))plt.xlabel("lambda")plt.ylabel("coefficients")plt.title("Effect of lambda on regression coefficients")plt.axis("tight")plt.legend()plt.show()
As \(\lambda\) increased on the x-axis, you can see the parameters, aka coefficients in colored lines \(\beta_1\)… \(\beta_5\) move towards zero. We will need to find the optimal value of \(\lambda\) for our model.
Now, let’s get to a real-world problem!
6.3 Example dataset
Our example dataset for the high-dimensional setting centers around this question: Can we use RNA gene expression predict response to a cancer treatment? If so, then we can use RNA gene expression as a biomarker to predict how cancer patients may respond to various cancer treatments. We use data from the Dependency Map Project, which has RNA gene expression profiles and cancer treatment responses on the largest collection of cancer cell line models.
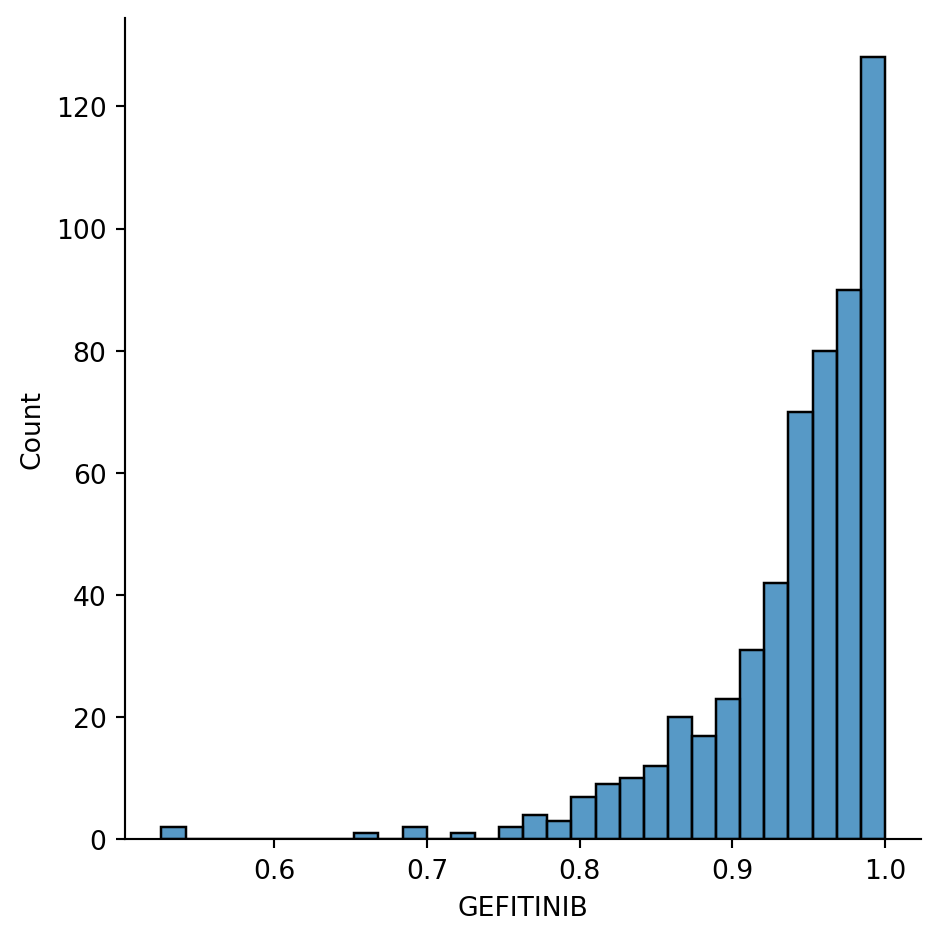
Let’s start looking at the cancer drug “Gefitinib”, which is a targeted therapy for non-small cell lung cancer with EGFR mutation and high levels of EGFR expression. We might expect to find the the gene EGFR highly predictive of Gefitinib response.
Let’s look at the distribution of our response. The drug response is measured in terms of Area Under the Curve (unrelated to the appendix of the ROC curve in the 3rd week), and a lower value indicates that the drug is more effective against the cancer.
Before we fit the model, we have to do some data transformations. In linear and logistic regression, all the parameter estimates for the models are scale equivariant. That is, if we multiply a predictor by a constant \(c\) and did not change anything else, the parameter estimate for that predictor will be scaled automatically \(\frac{1}{c}\) in the model training process. However, in regularization methods, because we are minimizing the Mean Squared Error and the magnitude of the parameters, the parameter estimates may change substantially if the scale of a predictor changes.
Therefore, the best practice is to first standardize the predictors before using regularization methods. We use the following code to ensure that each predictor has a mean of 0 and variance of 1:
With this data standardization, we are almost ready for lasso regression.
When using regularization methods, we have to figure out the value of \(\lambda\) (“lambda”), which dictates the balance between the Mean Squared Error and model parameters to be minimized. Similar to the parameters \(\beta\)s in the model, \(\lambda\) has to be learned in the training process also. However, there is something different about learning \(\lambda\):
One needs to pick the value of \(\lambda\) before the parameters \(\beta\)s are learned. They cannot be learned simultaneously.
There is no guidance on how to pick \(\lambda\): one has to try many values and see how the model performs. Whereas, for the \(\beta\)s, there is an algorithm (called “least squares”) that is deterministic for the optimal \(\beta\) value.
Therefore, we have to find the optimal \(\lambda\) to use. We can use Cross-Validation, which we learned from last week to explore the range of \(\lambda\) to use.
6.5 Lasso Regression
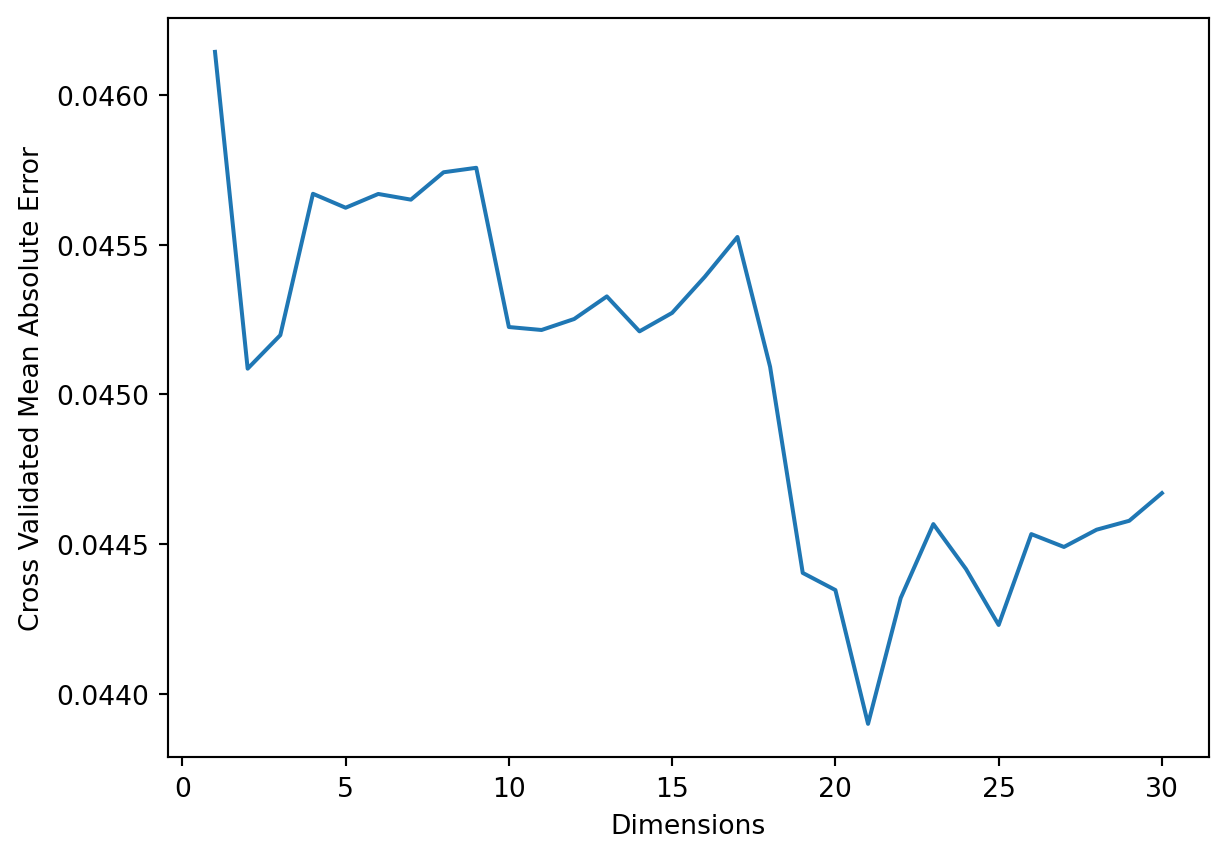
Let’s see how to implement cross validation in lasso regression. The LassoCV function will perform a search for the optimal \(\lambda\) for us via Cross Validation using whatever dataset you give it as a input. For speed, we use a 2-fold cross validation, but in general people use 5 to 10 fold cross-validation.
import timestart_time = time.perf_counter()reg = LassoCV(cv=2, random_state=0).fit(X_train_scaled, np.ravel(y_train))end_time = time.perf_counter() elapsed_time = end_time - start_timeprint(f"Elapsed time to fit model: {elapsed_time} seconds")
Elapsed time to fit model: 19.489783601 seconds
What is the \(\lambda\) learned in the cross validation?
print(reg.alpha_)
0.012408022529117964
(Notice in the code we refer to it as “alpha”. This is due to the a different in variable naming by Scikit-Learn.)
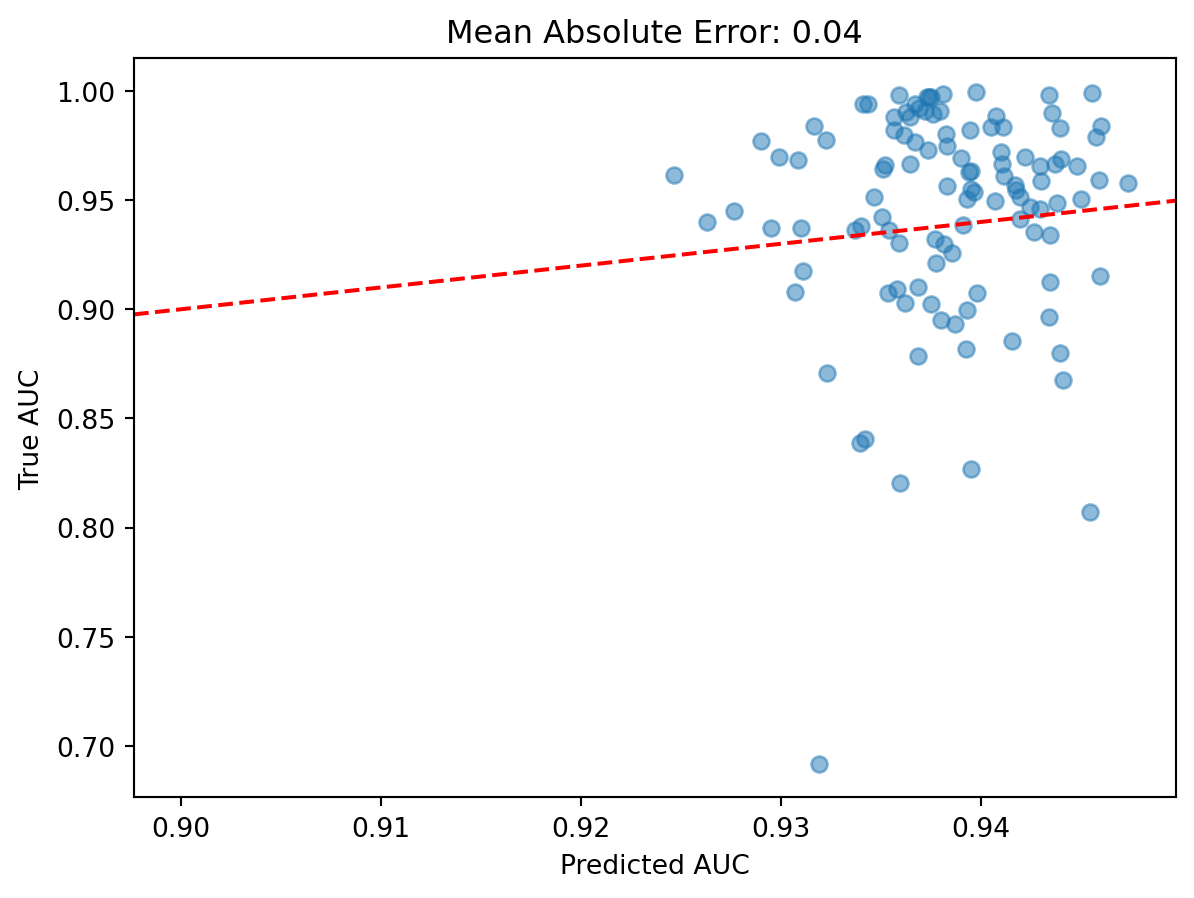
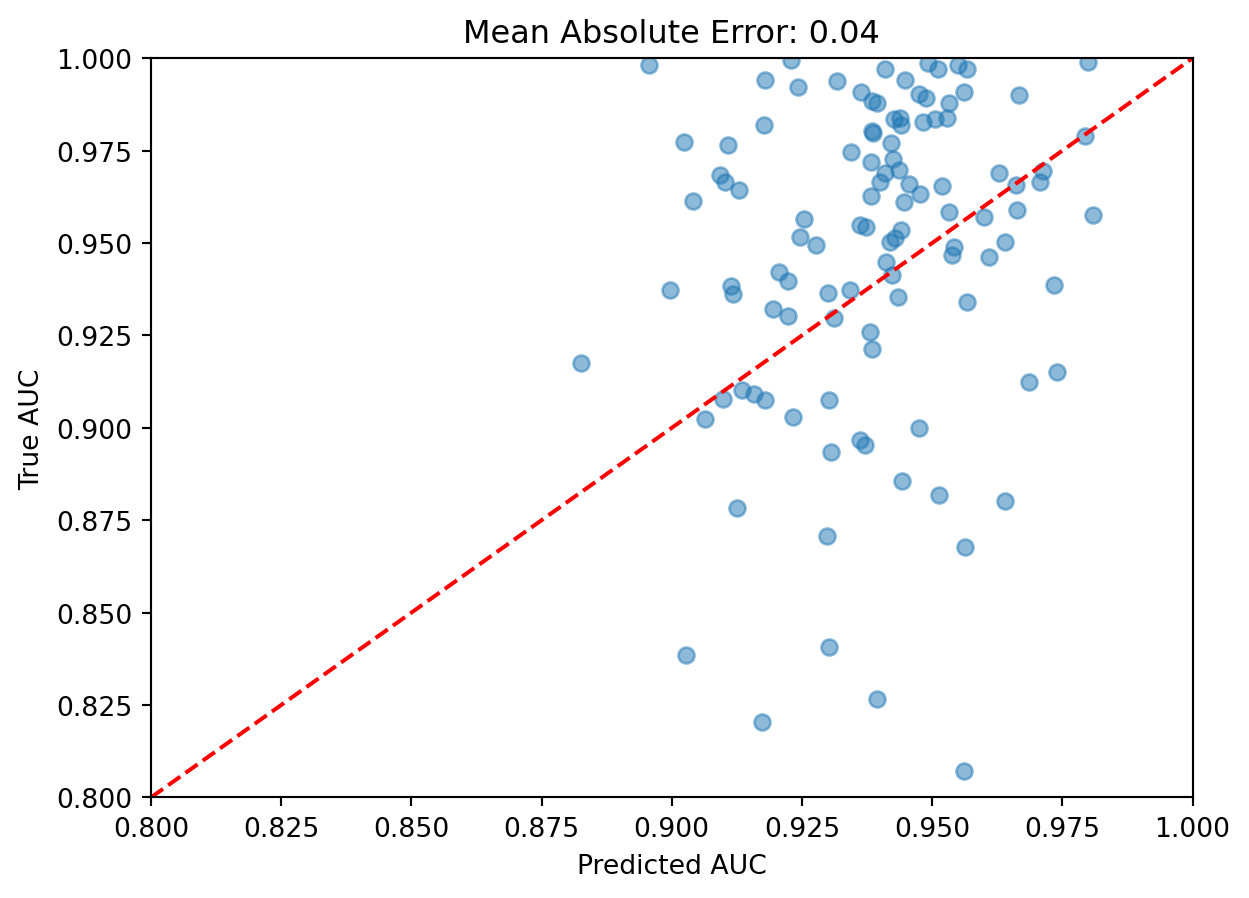
We expect that only a small subset of predictors end up being used for the lasso model. What are the genes that have non-zero coefficients?
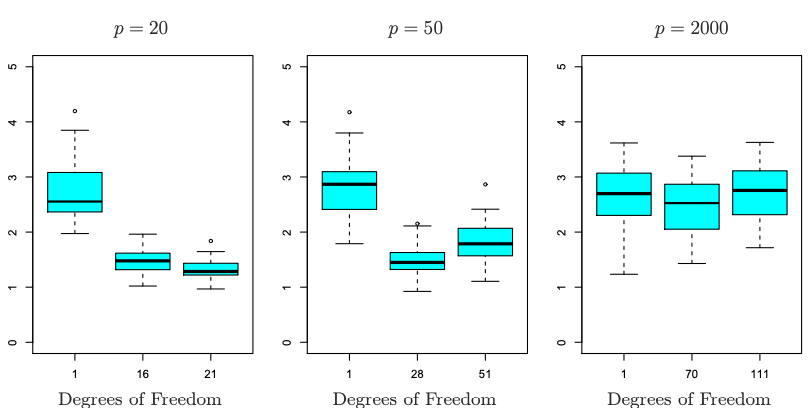
To understand the performance of a model, often people run simulations to see how it perform using a generated ground truth. In this simulation, 100 observations were generated with \(p=20\), \(p=50\), or \(p=2000\) features, of which 20 are truly associated with the outcome. Lasso was performed on each dataset, and the X-axis on the boxplot below shows the different number of predictors chosen (Degrees of freedom) based on different values of \(\lambda\), and the corresponding error on the Y-axis. We see that when the number of predictors is fairly low, Lasso was able to find a strong performing model with the number of predictors chosen close to the number of predictors truly associated with the outcome. When the number of predictors is high, the performance decreases. Even though Lasso is capable to tackling high dimensional problems, it can still get bogged by large number of dimensions.
Source: An Introduction to Statistical Learning, Ch. 6, by Gareth James, Daniela Witten, Trevor Hastie, Roebert Tibshirani, Jonathan Taylor.
6.7 Principal Components Analysis
Principal Components Analysis (PCA) is another way to reduce the number of predictors by generating a new, smaller set of predictors that seek to capture the majority of information in the original set of predictors. Suppose that you have 100 predictors, and you look at the total variance of the predictors. When one performs PCA, the process will take a linear combination of the 100 original predictors to yield a new predictor (the first principal component) that captures the most variability of the total variance: \(Z_1 = \sum^{100}_{i=1}\phi_{1i}X_i\) .Then, the second principal component is another combination of the 100 original predictors that captures the most of the remaining variability, and is perpendicular with the first principal component: \(Z_2 = \sum^{100}_{i=1}\phi_{2i}X_i\) And so on.
Thus, it is possible to take the first few principal components into a new regression model while capturing most of the total variance in the data; perhaps it is possible to use \(Z_1\), …, \(Z_5\) as our new predictors that capture most of the variability for \(X_1\), …, \(X_{100}\) This is done with the assumption that the variability of the predictors is correlated with the variance of the response - and it is usually a fair assumption as in high dimensional data.
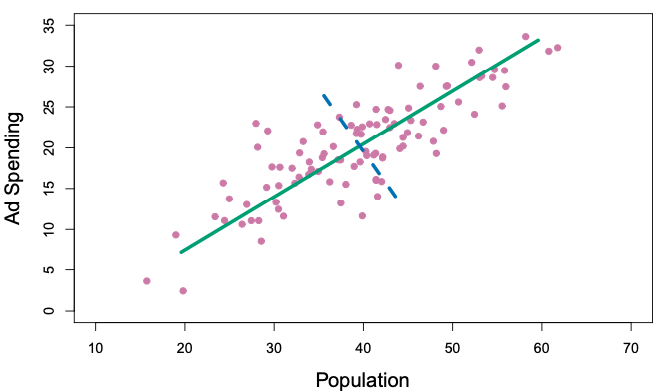
In the plots below, we look at two predictors, Population and Ad Spending. The first plot shows the scatterplot of the two predictors, with a green line drawn through as the dimension with the most variability in the sum of variance for the two predictors. This will be the first principal component: \(Z_1 = \phi_{11}X_1+\phi_{12}X_2\). Then, the dotted blue line, perpendicular to our green line, captures the remaining variability of the data. This will be the second principal component: \(Z_2 = \phi_{21}X_1+\phi_{22}X_2\).
Source: An Introduction to Statistical Learning, Ch. 6, by Gareth James, Daniela Witten, Trevor Hastie, Roebert Tibshirani, Jonathan Taylor.
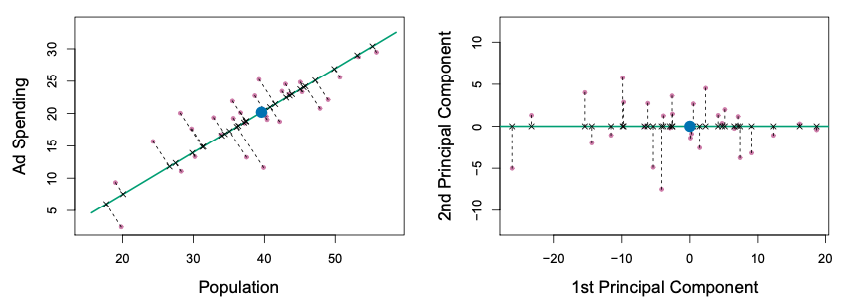
We can now transform our original data to these principal components, using the equations above. The transformed data looks like the bottom right panel in the figure below for the first two principal components. We can then use these two components are the predictors for our model. This example is to visually illustrate what PCA looks like for two dimensions, which is not very useful because there is not a lot of dimensional reduction to make with two predictors. One can imagine that with many predictors, we can pick a few of the top principal components that capture the majority of the predictors’ variance to reduce our predictor dimensional space.
Source: An Introduction to Statistical Learning, Ch. 6, by Gareth James, Daniela Witten, Trevor Hastie, Roebert Tibshirani, Jonathan Taylor.
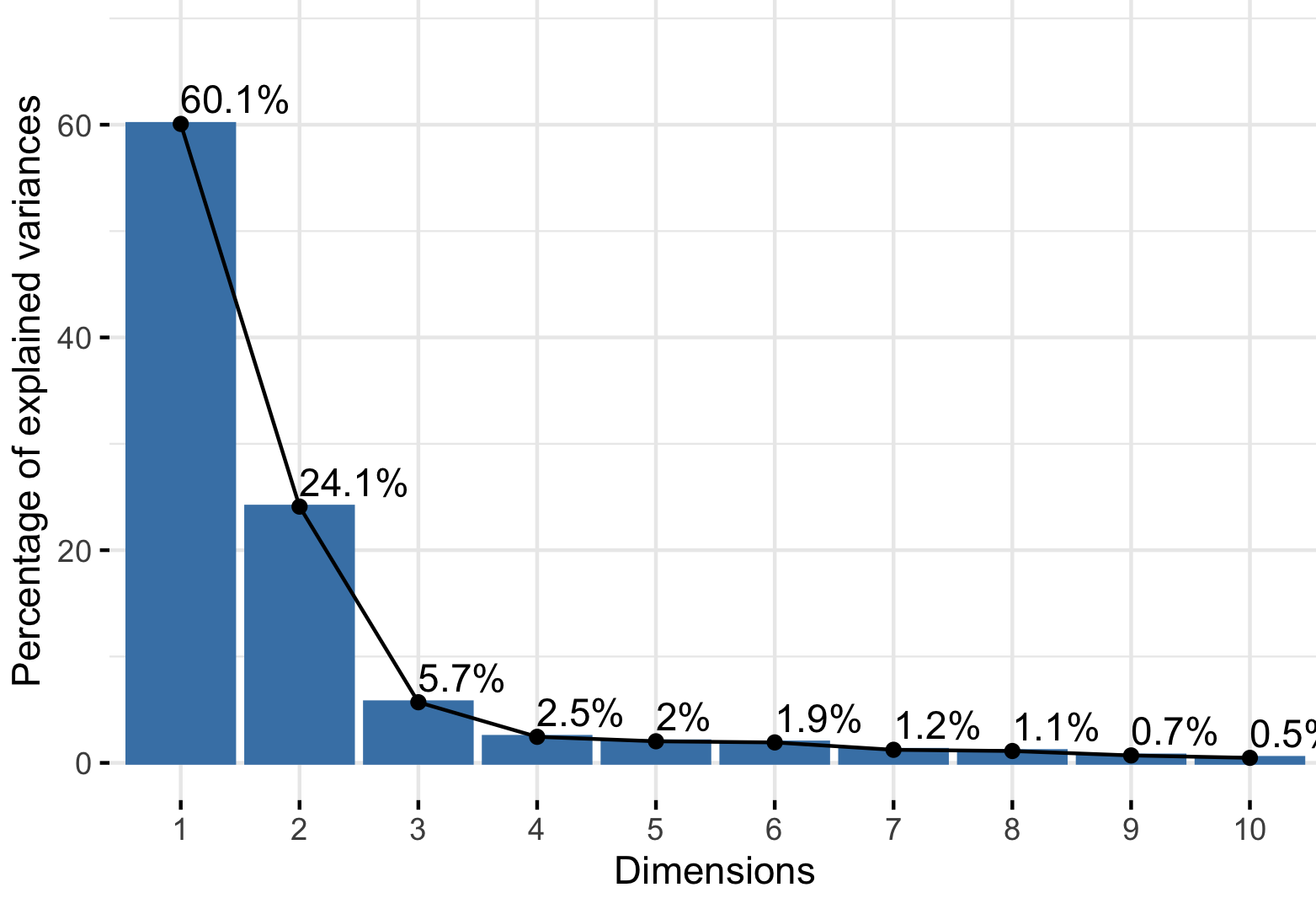
The choice of number of principal components to keep is usually decided by Cross Validation, or plotting a Scree Plot to find the number of principal components that the captured variance is not as significant. People typically limit the number of dimension just beyond the “elbow” shape of the Scree Plot.
The Lasso Regularization method is one of the many ways one can reduce the number of dimensions in your modeling process. Here are some other common methods of reducing the number of dimensions, and they don’t necessarily have to be mutually exclusive! It is common to combine multiple methods together:
We know from Linear and Logistic Regression that having co-linear predictors affect the performance of our models. We can remove the most correlated predictors.
A more nuanced way of doing this is to “remove the minimum number of predictors to ensure that all pairwise correlations are below a certain threshold”. The algorithm is as follows (from “Applied Predicted Modeling” by Kuhn and Johnson):
Calculate the correlation matrix of the predictors
Determine the two predictors associated with the largest absolute pairwise correlation (call them predictors A and B)
Determine the average correlation between A and other variables. Do the same for predictor B.
If A has a larger average correlation, remove it; otherwise remove B.
Repeat Steps 2-4 until no absolute correlations are above the threshold.
Predictors with extremely low variance are generally unhelpful predictors. Imagine that a predictor only contains one single value, which has a variance of 0. It would not relate at all to the response value. It is common practice to remove predictors with variance below a low threshold.
Removing predictors with a large number of missing values. Many regression methods will only run on samples with non-missing values. Giving a predictor with high number of missing values may reduce the number of available samples.
It is important to explore why there are missing values in the dataset, especially whether it is related to the response variable or not. If there is a strong trend, it may create strong bias in the model.
As a sidenote, one can consider imputing the missing values with educated guesses. This is a big topic in statistical literature that goes beyond the scope of the course. See this well-used reference in the R community.
6.10 Appendix: Ridge and Lasso regression
In regularization methods, the most common methods are Ridge and Lasso Regression. We only talk about Lasso Regression in this course, but in this appendix we expand in more technicality what is behind the scenes and what are some other variations.